Unless you live under the proverbial rock, you surely have come across Internet memes a few times. Memes are basically viral images, videos, slogans, etc., which might morph and evolve but eventually enter popular culture. When thinking about memes, most people associate them with ironic or irreverent images, from Bad Luck Brian to classics like Grumpy Cats.
Bad Luck Brian (left) and Grumpy Cat (right) memes.
Unfortunately, not all memes are funny. Some might even look as innocuous as a frog but are in fact well-known symbols of hate. Ever since the 2016 US Presidential Election, memes have been increasingly associated with politics.
Pepe The Frog meme used in a Brexit-related context (left), Trump as Perseus beheading Hillary as Medusa (center), meme posted by Trump Jr. on Instagram (right).
But how exactly do memes originate, spread, and gain influence on mainstream media? To answer this question, our recent paper (“On the Origins of Memes by Means of Fringe Web Communities”) presents the largest scientific study of memes to date, using a dataset of 160 million images from various social networks. We show how “fringe” Web communities like 4chan’s “politically incorrect board” (/pol/) and certain “subreddits” like The_Donald are successful in generating and pushing a wide variety of racist, hateful, and politically charged memes.
Earlier this year, Shehar Bano summarised our work on scanning the Internet and categorising IP addresses based on how “alive” they appear to be when probed through different protocols. Today it was announced that the resulting paper won the Applied Networking Research Prize, awarded by the Internet Research Task Force “to recognize the best new ideas in networking and bring them to the IETF and IRTF”. This occasion seems like a good opportunity to recall what more can be learned from the dataset we collected, but which couldn’t be included in the paper itself. Specifically, I will look at the multi-dimensional aspects to “liveness” and how this can be represented through holographic visualisation.
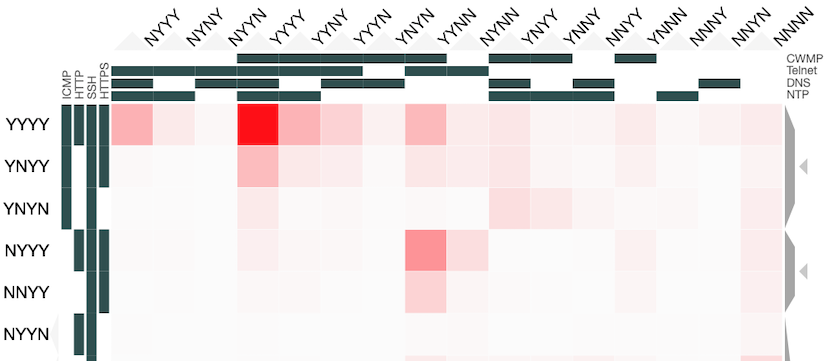
One of the most interesting uses of these experimental results was the study of correlations between responses to different combinations of network protocols. This application was only possible because the paper was the first to simultaneously scan multiple protocols and so give us confidence that the characteristics measured are properties of the hosts and the networks they are on, and not artefacts resulting from network disruption or changes in IP address allocation over time. These correlations are important because the combination of protocols responded to gives us richer information about the host itself when compared to the result of a scan of any one protocol. The results also let us infer what would likely be the result of a scan of one protocol, given the result of a scan of different ones.
In these experiments, 8 protocols were studied: ICMP, HTTP, SSH, HTTPS, CWMP, Telnet, DNS and NTP. The results can be represented as 28=256 values placed in a 8-dimensional space with each dimension indicating whether a host did or did not respond to a probe of that protocol. Each value is the number of IP addresses that respond to that particular combination of network protocols. Abstractly, this makes perfect sense but representing an 8-d space on a 2-d screen creates problems. The paper dealt with this issue through dimensional reduction, by projecting the 8-d space on to a 2-d chart to show the likelihood of a positive response to a probe, given a positive response to probe on another single protocol. This chart is useful and easy to read but hides useful information present in the dataset.
Over the past few years, food and drink have become an essential part of our social media footprints. This shouldn’t come as a surprise – after all, eating and drinking were social activities long before the first #foodporn hashtag on Instagram. In fact, scientificstudies have showed that what we gobble up or gulp down is shaped by social and regional influences, and how we tend to mirror habits of people with shared social connections.
Nowadays, we have an unprecedented opportunity to study eating & drinking habits at scale, as people share more and more of that online, both on popular social networks like Instagram, Twitter, and Facebook, but also on “dedicated” apps like Yummly or Untappd.
Along these lines is our recent paper, “Of Wines and Reviews: Measuring and Modeling the Vivino Wine Social Network,” recently presented at the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2018) in Barcelona. The study – co-authored by former UCL undergraduate student Neema Kotonya, Italian wine journalist Paolo De Cristofaro, and UCL faculty Emiliano De Cristofaro – presented a preliminary study showcasing big-data and social network analysis of how users worldwide consume, rate, and provide reviews of wines. We did so through the lens of Vivino, a popular wine social network. (And, yes, Paolo is Emiliano’s brother! 😊)
What is Vivino?
Vivino.com is an online community for wine enthusiasts, available both as a web and a mobile application. It was founded in 2009 by Heini Zachariassen, with his colleague Theis Sondergaard joining in 2010. In a nutshell, Vivino allows users to review and purchase wines through third-party vendors. The mobile app also provides a “wine scanner” functionality – i.e., users can upload pictures of wine labels and access reviews and details about the wine/winery.
But Vivino is actually a social network, as it allows wine enthusiasts to communicate with and follow each other, as well as share reviews and recommendations. As of September 2018, it had 32 million users, 9.7 million wines covering a multitude of wine styles, grapes, and geographical regions, as well as 103.7 million ratings and almost 35 million reviews.
In October 2016, UCL’s Information Services Division (ISD) implemented a new password policy to encourage users to choose stronger passwords. The policy links password lifetime (the time before the password expires) to password strength: The stronger the password, the longer the lifetime.
We (Ingolf Becker, Simon Parkin and M. Angela Sasse) decided to collaborate with the Information Services Division to study the effect of this policy change, and the results were published at USENIX Security this week. We find that users appreciate the choice and respond to the policy by choosing stronger passwords when changing passwords. Even after 16 months the mean password lifetime at UCL continues to increase, yet stronger passwords also lead to more password resets.
The new policy
In the new policy, passwords with Shannon Information Entropy of 50 bits receive a lifetime of 100 days, and passwords with 120 bits receive a lifetime of 350 days:
Additionally, the new policy penalises the lifetime of passwords containing words from a large dictionary.
Users play the game
We analysed the password lifetime – what we will refer to from here on in as the ‘password strength’ – of all password change and reset events of all pseudonymised users at UCL. The following figure shows the mean password expiration of all users over time, smoothed by 31-day moving averages:
A small drop in password strength was observed between November ’16 and February ’17, as users were moved on to and generally became accustomed to the new system; the kinds of passwords they would have been used to using were at that point not getting them as many days as before (hence the drop). After February ’17, the mean strength increases from 145 days to 170 days in 12 months – an increase of 6.9 bits of entropy. This strongly suggests that users have generally adapted slowly to the new password policy, and eventually make use of the relatively new ability to increase password lifetime by expanding and strengthening their passwords.
Science is generally accepted to operate by conducting specially-designed structured observations (such as experiments and case studies) and then interpreting the results to build generalised knowledge (sometimes called theories or models). An important, nay necessary, feature of the social operation of science is transparency in the design, conduct, and interpretation of these structured observations. We’re going to work from the view that security research is science just like any other, though of course as its own discipline it has its own tools, topics, and challenges. This means that studies in security should be replicable, reproducible, or at least able to be corroborated. Spring and Hatleback argue that transparency is just as important for computer science as it is for experimental biology. Rossow et al. also persuasively argue that transparency is a key feature for malware research in particular. But how can we judge whether a paper is transparent enough? The natural answer would seem to be if it is possible to make a replication attempt from the materials and information in the paper. Forget how often the replications succeed for now, although we know that there are publication biases and other factors that mess with that.
So how many security papers published in major conferences contain enough information to attempt a reproduction? In short, we don’t know. From anecdotal evidence, Jono and a couple students looked through the IEEE S&P 2012 proceedings in 2013, and the results were pretty grim. But heroic effort from a few interested parties is not a sustainable answer to this question. We’re here to propose a slightly more robust solution. Master’s students in security should attempt to reproduce published papers as their capstone thesis work. This has several benefits, and several challenges. In the following we hope to convince you that the challenges can be mitigated and the benefits are worth it.
This should be a choice, but one that master’s students should want to make. If anyone has a great new idea to pursue, they should be encouraged to do so. However, here in the UK, the dissertation process is compressed into the summer and there’s not always time to prototype and pilot study designs. Selecting a paper to reproduce, with a documented methodology in place, lets the student get to work faster. There is still a start-up cost; students will likely have to read several abstracts to shortlist a few workable papers, and then read these few papers in detail to select a good candidate. But learning to read, shortlist, and study academic papers is an important skill that all master’s students should be attempting to, well, master. This style of project would provide them with an opportunity to practice these skills.
Briefly, let’s be clear what we mean by reproduction of published work.
Reproduction isn’t just one thing. There’s reproduce and replicate and corroborate and controlled variation (see Feitelson for details). Not everything is amenable to reproduction. For example, case studies (such as attack papers) or natural experiments are often interesting because they are unique. Corroborating some aspect of the case may be possible with a new study, and such study is also valuable. But this not the sort of reproduction we have in mind to advocate here.
Internet-wide scanning (or probing) has emerged as a key measurement technique to study a diverse set of the Internet’s properties, including address space utilization, host reachability, topology, service availability, vulnerabilities, and service discrimination. But despite its widespread use and critical importance for Internet measurement, we still lack a clear understanding of IP liveness—whether a target IP address responds to a probe packet. What type of probe packets should we send if we, for example, want to maximize the responding host population? What type of responses can we expect and which factors determine such responses? What degree of consistency can we expect when probing the same host with different probe packets?
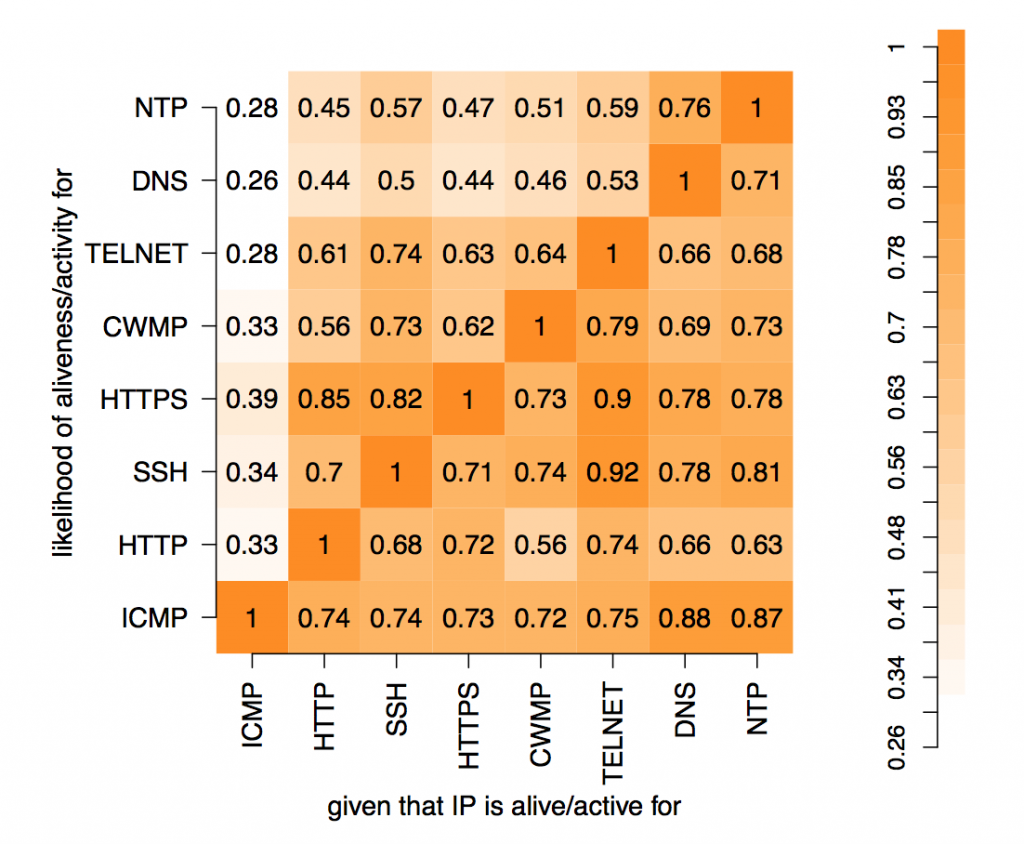
In our recent paper Scanning the Internet for Liveness, we presented a systematic analysis of liveness and how it shows up in active scanning campaigns. We developed a taxonomy of liveness which we employed to develop a method to perform concurrent IPv4 scans using ICMP, five TCP-based, and two UDP-based protocols, capturing all responses to our probes. Our key findings are:
Responsive host populations are highly sensitive to the choice of probe. While ICMP discovers the highest number of raw IPs, our TCP and UDP measurements exclusively contribute a fifth to the total population of responsive hosts.
Collecting ICMP Error messages for TCP and UDP scans increases the responsive population by more than 13%, and provides new opportunities to interpret scan results.
At the transport layer, our concurrent measurements reveal that the majority of hosts exhibit inconsistent behaviour when probed on different ports, and that capturing negative responses significantly improves scanning completeness.
Our concurrent scans allow us to identify nearly 2M tarpits (IPs masquerading as fake hosts) that would bias measurements that do not take them into account.
Our study of cross-protocol liveness shows that responsiveness for some protocols is correlated, suggesting that the same seed set of responsive IP addresses can be potentially used to bootstrap multiple highly-correlated target populations to reduce scan traffic.
This work recently appeared in the April 2018 issue of ACM SIGCOMM Computer Communication Review (CCR), and was conducted in collaboration with Philipp Richter (MIT), Mobin Javed (LUMS Pakistan, ICSI Berkeley), Srikanth Sundaresan (Princeton University), Zakir Durumeric (Stanford University), Steven J. Murdoch (University College London), Richard Mortier (University of Cambridge) and Vern Paxson (UC Berkeley, ICSI Berkeley). Overall, this study yields practical insights and methodological improvements for the design and the execution of active Internet measurement studies. We released the code and data of this work as open source to allow for reproducibility of the results, and to enable further research.
Zcash is a cryptocurrency whose main feature is a “shielded pool” that is designed to provide strong anonymity guarantees. Indeed, the cryptographic foundations of the shielded pool are based in highly-regarded academic research. The deployed Zcash protocol, however, allows for transactions outside of the shielded pool (which, from an anonymity perspective, are identical to Bitcoin transactions), and it can be easily observed from blockchain data that the majority of transactions do not use the pool. Nevertheless, users of the shielded pool should be able to treat it as their anonymity set when attempting to spend coins in an anonymous fashion.
In a recent paper, An Empirical Analysis of Anonymity in Zcash, we (George Kappos, Haaroon Yousaf, Mary Maller, and Sarah Meiklejohn) conducted an empirical analysis of Zcash to further our understanding of its shielded pool and broader ecosystem. Our main finding is that is possible in many cases to identify the activity of founders and miners using the shielded pool (who are required by the consensus rules to put all newly generated coins into it). The implication for anonymity is that this activity can be excluded from any attempt to track coins as they move through the pool, which acts to significantly shrink the effective anonymity set for regular users. We have disclosed all our findings to the developers of Zcash, who have written their own blog post about this research. This work will be presented at the upcoming USENIX Security Symposium.
What is Zcash?
In Bitcoin, the sender(s) and receiver(s) in a transaction are publicly revealed on the blockchain. As with Bitcoin, Zcash has transparent addresses (t-addresses) but gives users the option to hide the details of their transactions using private addresses (z-addresses). Private transactions are conducted using the shielded pool and allow users to spend coins without revealing the amount and the sender or receiver. This is possible due to the use of zero-knowledge proofs.
Like Bitcoin, new coins are created in public “coingen” transactions within new blocks, which reward the miners of those blocks. In Zcash, a percentage of the newly minted coins are also sent to the founders (a predetermined list of Zcash addresses owned by the developers and embedded into the protocol).
The island of Cyprus, situated in the east of the Mediterranean sea, has always been an important commercial and information exchange hub. Today, this is reflected on the large number of submarine cables that facilitate telecommunications with neighboring countries (Greece, Turkey, Egypt, Israel, Syria, and Lebanon) and with the rest of the world (reaching as far as India, South Korea, and Australia). Nevertheless, the Republic of Cyprus (RoC) is officially regarded as a freedom of expression safe haven, where “Internet is completely free of any specific regulation”. Unfortunately, Cypriot netizens claim that such statements couldn’t be further from the truth.
In recent years, Internet Service Providers (ISPs) in RoC have implemented an Internet filtering infrastructure to comply with the laws and regulations implied by the National Betting Authority (NBA). In an effort to understand the capacity of this infrastructure, a multi-disciplinary group of volunteers from the hack66 Observatory in Nicosia has collected and analyzed connectivity measurements from end-user connections on a variety of websites and services. Their report was presented at the 7th International Conference on e-Democracy.
For their experiments, the hack66 Observatory team put together a testlist comprising of domains from the National Betting Authority blocklist, the CitizenLab lists for Greece and Turkey, and WordPress blogs banned in Turkey as reported at the Lumen Database. The analysis was based on over 45,000 measurements from four residential ISPs operating in the Republic of Cyprus, that were anonymously submitted using a custom OONI probe during the months of March to May 2017. In addition, the team collected data using open DNS resolvers in Cyprus. Early findings suggest that the most common blocking method is DNS hijacking. Furthermore, the measurements indicate that some of the ISPs have deployed middle-boxes – network components capable of performing censorship, traffic manipulation or surveillance.
A closer inspection on the variations of the censorship mechanism implementations among ISPs raised concerns with regard to transparency and privacy: some ISPs do not inform users why a blocked website is not accessible; while others redirect requests to a web server controlled by the NBA, that could in turn log user identifiers such as their IP address. Similarly, the hack66 Observatory team was able to identify a number of unreported Internet censorship cases, entries in the NBA blocklist that either are invalid or that require sophisticated blocking techniques, and collateral damage due to blocking of email delivery to the regulated domains.
Understanding the case of Internet freedom in Cyprus becomes more complicated when the geopolitical situation is taken into consideration. Apart from the Republic of Cyprus, the island of Cyprus is divided into three other segments: the self-declared Turkish Republic of Northern Cyprus; the United Nations-controlled Green Line buffer zone; and the Sovereign Base Areas of Akrotiri and Dhekelia that remain under British control for military purposes. Measurements from the Multimax ISP operating in the area occupied by Turkey indicate network interference practices similar to those of mainland Turkey. This could be interpreted as the existence of two distinct regimes in terms of information policy on the island of Cyprus. No volunteers submitted measurements from the UN buffer zone or the British Sovereign bases. However, it is known via the Snowden revelations that GCHQ is operating a wiretap base in Cyprus codenamed “SOUNDER”, jointly funded by the NSA.
The purpose of the hack66 Observatory is to “to collect and analyze data, and routes of data through EMEA, […] in order to promote evidence based policy making”. The timing is just right, given the recent RoC government announcement of a new bill in the making, to regulate media operations and stop fake news. With their report, the hack66 Observatory aims to provide policy makers with a valuable asset for understanding the limitations and implications of the existing censorship infrastructure, and to start a debate around Internet freedom on the entirety of the island of Cyprus.
On July 2nd, 2017, Donald Trump, the President of the United States of America, tweeted a short video clip of him punching out a CNN logo. The video was modified from an appearance that Mr. Trump made at a Wrestlemania event. It originally appeared on Reddit’s /r/The_Donald subreddit. Although The_Donald was infamous in some circles, the uproar the image caused was many’s first introduction to a community of users that have had a striking amount of influence on the world stage. While memes like the one birthed from The_Donald are worrying, but mostly harmless, a shocking amount of disinformation (“fake news”) is also created by and spread from smaller, fringe Web communities that have relatively outsized influence on the greater Web.
In a nutshell, the explosion of the Web has commoditized the creation of false information and enabled it to spread like wild fire at unprecedented scale. After a decade and a half of experience with social media platforms, bad actors have honed their techniques and been surprisingly adept at crafting messages that at best make it difficult to distinguish between fact and fiction, and at worst propagate dangerous falsehoods.
While recent discourse has tried to blur the lines between real and fake news, there are some fundamental differences. For example, the simple fact that fake news has to be created in the first place. Real news, even opinion pieces, is based around reporting and interpretation of factual material. Not to dismiss the efforts of journalists, but, the fact remains: they are not responsible for generating stories from whole cloth. This is not the case with the type of misinformation pushed by certain corners of the Web.
Consider recent events like the death of Heather Heyer during the Charlottesville protests earlier this year. While facts had to be discovered, they were facts, supported by evidence gathered by trained professionals (both law enforcement and journalists) over a period of time. This is real news. However, the facts did not line up with the far right political ideology espoused on 4chan’s /pol/ board (or if we want to play Devil’s Advocate, it made for good trolling material), and thus its users set about creating alternative narratives. Immediately they began working towards a shocking, to the uninitiated, nearly singular goal: deflect from the fact that a like mind committed a heinous act of violence in any way possible.
/pol/ users mobilized in a perverse, yet fascinating, use of the Web. Dozens of, often conflicting, discussion threads putting forth alternative theories of Ms. Heyer’s killing, supported by everything from pure conjecture, to dubious analysis of mobile phone video and pictures, to impressive investigations discovering personal details and relationships of victims and bystanders. Over time, pieces of the fabrication were agreed upon and tweaked until it resembled in large part a plausible, albeit eyebrow raising, false reality ready for consumption by the general public. Further, as bits of the narrative are debunked, it continues to evolve, weeks after the actual facts have been established.
One month after Heather Heyer’s killing, users on /pol/ were still pushing fabricated alternative narratives of events.
The Web Centipede
There are many anecdotal examples of smaller communities on the Web bubbling up and influencing the rest of the Web, but the plural of anecdote is not data. The research community has studied information diffusion on specific social media platforms like Facebook and Twitter, and indeed each of these platforms is under fire from government investigations in the US, UK, and EU, but the Web is much bigger than just Facebook and Twitter. There are other forces at play, where false information is incubated and crafted for maximum impact before it reaches a mainstream audience. Thus, we set out to measure just how this influence flows in a systematic and methodological manner, analyzing how URLs from 45 mainstream and 54 alternative news sources are shared across 8 months of Reddit, 4chan, and Twitter posts.
While we made many interesting findings, there are a few we’ll highlight here:
Reddit and 4chan post mainstream news URLs at over twice the rate than Twitter does, and 4chan in particular posts alternative news URLs at twice the rate of Twitter and Reddit.
We found that alternative news URLs spread much faster than mainstream URLs, perhaps an artifact of automated bots.
While 4chan was usually the slowest to a post a given URL, it was also the most successful at “reviving” old stories: if a URL was re-posted after a long period of time, it probably showed up on 4chan originally.
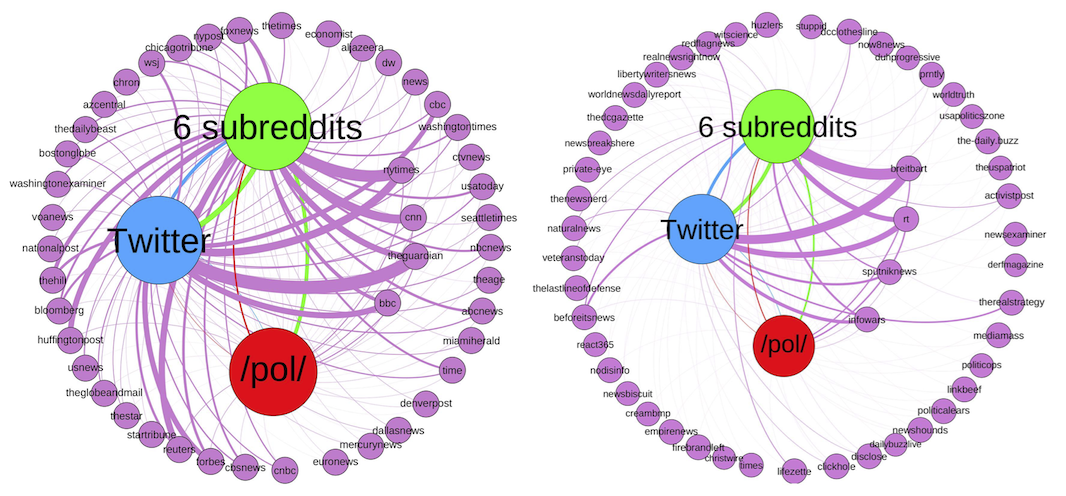
Graph representation of news ecosystem for mainstream news domains (left) and alternative news domains (right). We create two directed graphs, one for each type of news, where the nodes represent alternative or mainstream domains, as well as the three platforms, and the edges are the sequences that consider only the first-hop of the platforms. For example, if a breitbart.com URL appears first on Twitter and later on the six selected subreddits, we add an edge from breitbart.com to Twitter, and from Twitter to the six selected subreddits. We also add weights on these edges based on the number of such unique URLs. Edges are colored the same as their source node.
Measuring Influence Through the Lens of Mainstream and Alternative News
While comparative analysis of news URL posting behavior provides insight into how Web communities connect together like a centipede through which information flows, it is not sufficiently powerful to quantify the specific levels of influence they have.
I was at the EuroUSEC ’17 workshop in Paris at the end of April. Our own Angela Sasse was also there to deliver the keynote talk, and Ruba Abu-Salma presented our paper “The Security Blanket of the Chat World: An Analytic Evaluation and a User Study of Telegram” (which was based on research by undergraduate students studying UCL’s COMP3096 “Research Group Project” module). I presented secondary analysis, conducted with Ingolf Becker and Angela Sasse, of a survey deployed at a large partner organisation. This analysis builds on research we presented at the Symposium on Usable Privacy and Security (SOUPS) in 2016. Based on survey responses and voluntary free-text comments, we saw potential for employees to inform policy from the ‘ground up’, in contradiction to the current trend for identifying security champions as local representatives of pre-determined policy.
Top-down security policies
Organisational policies are intended to promote a unified approach to security, one that all the organisation’s employees are expected to follow. If security procedures and mechanisms are unusable, policies risk being seen as impossible to follow, or may be sidelined if they lack clear relevance to business goals. This can result in deliberate or unwitting non-compliance, and workarounds to prescribed procedures.
Organisations may promote security champions, as local representatives to promote policy in their part of the organisation. However, these security champions can be effective only if policy is workable. Encouraging ‘top down’ policy compliance assumes that policy is correct, complete, and appropriate. It also assumes that policy applies to everyone equally and that employees have no role to play in shaping effective policy. Our analysis explores the potential for employees to inform effective policies, in particular whether it was possible to (i) identify local pockets of security expertise, and (ii) target engagement with employees that involves them in the creation of workable security solutions.
Identifying security champions ‘from the ground up’
Level
Attitude
Approach
1
Uninfluenced
Security behaviour is driven by personal knowledge.
2
Technically Controlled
Technical controls enforce compliance with policy.
3
Ad-hoc Knowledge and Application
Shallow understanding of policy.
Knowledge absorbed from surrounding work environment.
4
Policy Compliant
Comprehensive knowledge and understanding of policy.
Willing policy compliance.
Role model for organisation’s security culture.
5
Active Approach to Security
Actively promote and advance security culture.
Intent of policy carried into work activities
Leverage well-understood values that support both security and business.
Employee security – Attitude-Levels. We studied an organisation with IT systems, so there were no participants at Level 1
A scenario-based survey was deployed in the partner company. Scenarios were based upon in-depth interviews with employees that explored security behaviours in the workplace. Each scenario involved a dilemma, where fixed options described different responses and included an element of non-compliance or an implicit cost. Participant choices indicate their Behaviour Type (above) and Attitude Level (below), which we recorded across groups of employees to characterise the security culture of the organisation and in four specific divisions. Both interviews and surveys represent a cross-section of divisions, locations, and age groups. We collected 608 survey responses; crucially, the survey allowed participants to comment on the scenarios and the available options – we also looked at 267 additional free-text comments that were provided.
Behaviour-Type
Description
Individualists
Rely on self for solutions
Egalitarians
Rely on social or group solutions
Hierarchists
Rely on existing systems or technologies
Fatalists
Take a ‘naive’ approach, that their actions are not significant in creating outcomes