The 2020 COVID-19 pandemic required society to make substantial changes in how people lived, worked and studied, while facing uncertainty in both the behaviour of the virus and the risk it posed. To help inform their response, between October 2020 and May 2022, University College London collected a daily count of confirmed COVID-19 cases among its staff and students. This gave a snapshot of the current status, but the appropriate action depends not only on absolute infection counts but also on trends and the relationship to the national and international position.
As part of my contribution to UCL’s pandemic response, I collected these daily statistics, resolved data quality issues, and created interactive visualisations to identify and illustrate trends in COVID cases among UCL staff and students. These were used within the Computer Science department, throughout UCL, and beyond, to inform measures that allowed UCL to continue to fulfil its education and research mission while protecting its members and society as a whole.
Along with this blog post, I’m releasing a historical archive of these statistics and, to put the dataset in proper context, a record of the pandemic-response newsletter published by UCL. Both are preserved as a Zenodo artefact.
Why a campus-scale signal was worth having
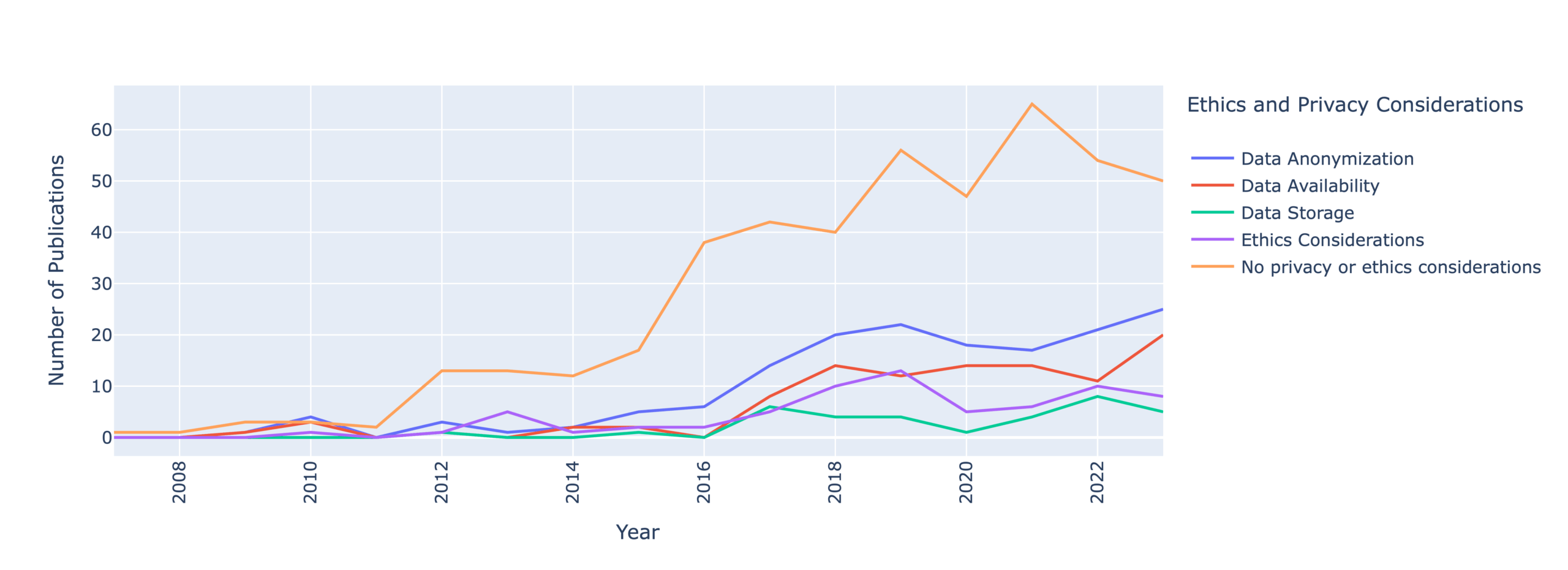
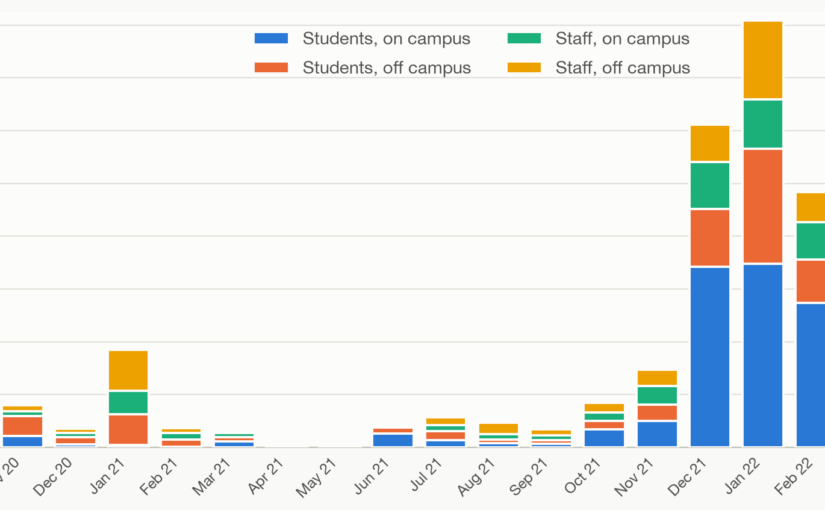
National statistics answered a national question. They could not tell a department whether it was sensible to hold a seminar in person next week, run a laboratory, or bring a team back on site, because they described the country, at a lag, rather than the building you actually worked in. Planning needed a signal at the scale of the decision. That mismatch, between figures gathered to answer a national question and choices that had to be made building by building, is why a local signal had to be built at all rather than drawn from what already existed. UCL’s case statistics supplied one, separated into staff and students and, crucially, into those who had recently been on campus and those who had not. The primary statistics I published were a seven-day rolling total, which smoothed out noise and day-of-week effects presenting in the daily count. These charts behaved as an early-warning line, moving before a rise was widely apparent, and for the specific community whose risk was being weighed.
What the trends actually showed
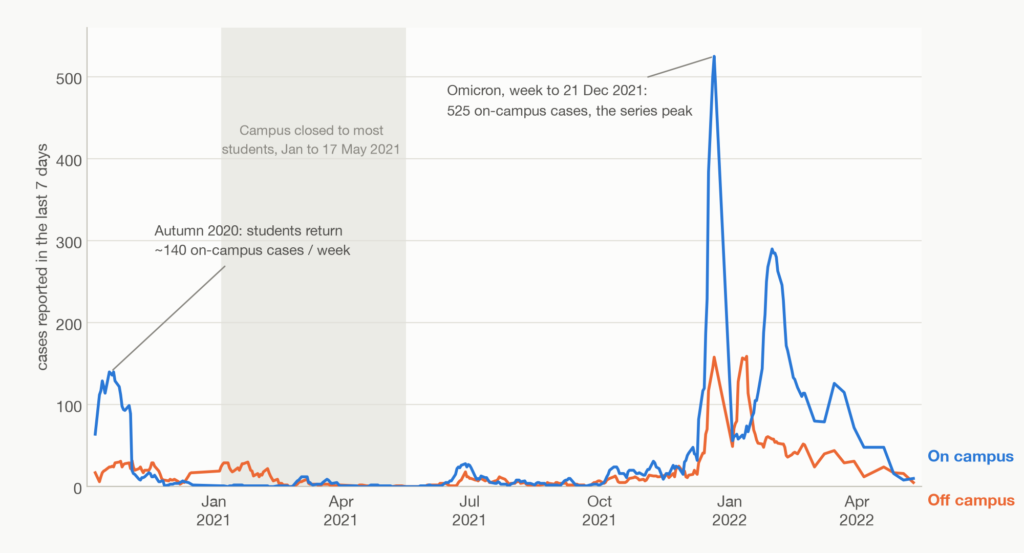
Three features of the series show what made it worth watching. The first is early warning. The data was first published with the autumn 2020 start-of-term surge, where student on-campus cases climbed to roughly 140 a week through October: the wave predicted from the mass return of students, becoming visible in the local figures before it was a national headline.
Continue reading UCL’s response to the COVID-19 pandemic: a historical archive
")