Sharing data can often enable compelling applications and analytics. However, more often than not, valuable datasets contain information of sensitive nature, and thus sharing them can endanger the privacy of users and organizations.
A possible alternative gaining momentum in the research community is to share synthetic data instead. The idea is to release artificially generated datasets that resemble the actual data — more precisely, having similar statistical properties.
So how do you generate synthetic data? What is that useful for? What are the benefits and the risks? What are the fundamental limitations and the open research questions that remain unanswered?
All right, let’s go!
How To Safely Release Data?
Before discussing synthetic data, let’s first consider the “alternatives.”
Anonymization: Theoretically, one could remove personally identifiable information before sharing it. However, in practice, anonymization fails to provide realistic privacy guarantees because a malevolent actor often has auxiliary information that allows them to re-identify anonymized data. For example, when Netflix de-identified movie rankings (as part of a challenge seeking better recommendation systems), Arvind Narayanan and Vitaly Shmatikov de-anonymized a large chunk by cross-referencing them with public information on IMDb.
Aggregation Another approach is to share aggregate statistics about a dataset. For example, telcos can provide statistics about how many people are in some specific locations at a given time — e.g., to assess footfall and decide where one should open a new store. However, this is often ineffective too, as the aggregates can still help an adversary learn something about specific individuals.
Differential Privacy: More promising attempts come from providing access to statistics obtained from the data while adding noise to the queries’ response, guaranteeing differential privacy. However, this approach generally lowers the dataset’s utility, especially on high-dimensional data. Additionally, allowing unlimited non-trivial queries on a dataset can reveal the whole dataset, so this approach needs to keep track of the privacy budget over time.
Types of Synthetic Data
There are different approaches to generating synthetic data. Derek Snow of the Alan Turing Institute lists three main methods:
1) Hand-engineered methods identify an underlying distribution from real data using expert opinion and seek to imitate it.
2) Agent-based models establish known agents and allow them to interact according to prescribed rules hoping that this interaction would ultimately amount to distribution profiles that look similar to the original dataset.
3) Generative machine models learn how a dataset is generated using a probabilistic model and create synthetic data by sampling from the learned distribution.
In the rest of this post, we will focus on generative models, as they are generally considered the state of the art. (Additional methods include imputation models.)
Background: Generative vs. Discriminative Models
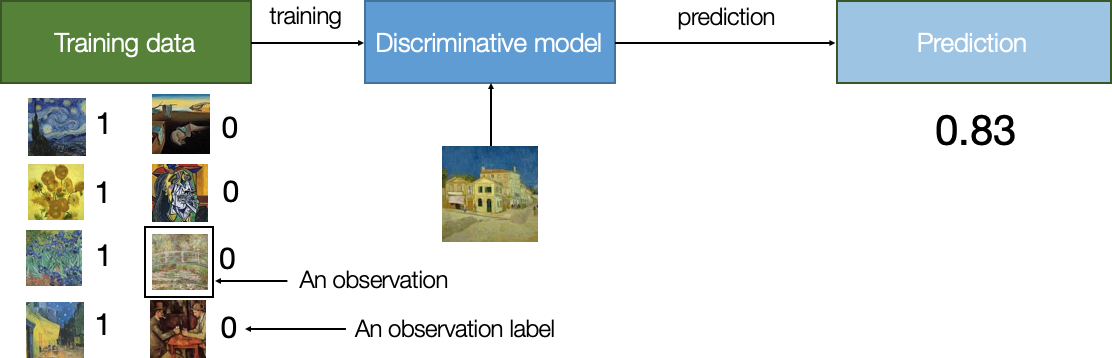
A good way to understand how generative models work is to look at how they differ from discriminative models. Let’s say we want to recognize which paintings are by Vincent Van Gogh. First, we label a dataset of artworks we know whether or not were painted by Van Gogh. Then, we train a discriminative model to learn that specific characteristics (e.g., colors, shapes, or textures) are typical of Van Gogh. We can now use that model to predict whether Van Gogh authored any painting.
Now let’s say we want to generate a new image of a horse that doesn’t exist but still looks real. We train a generative model to learn what horses look like. To do so, we need a dataset with many examples (observations) of horses.
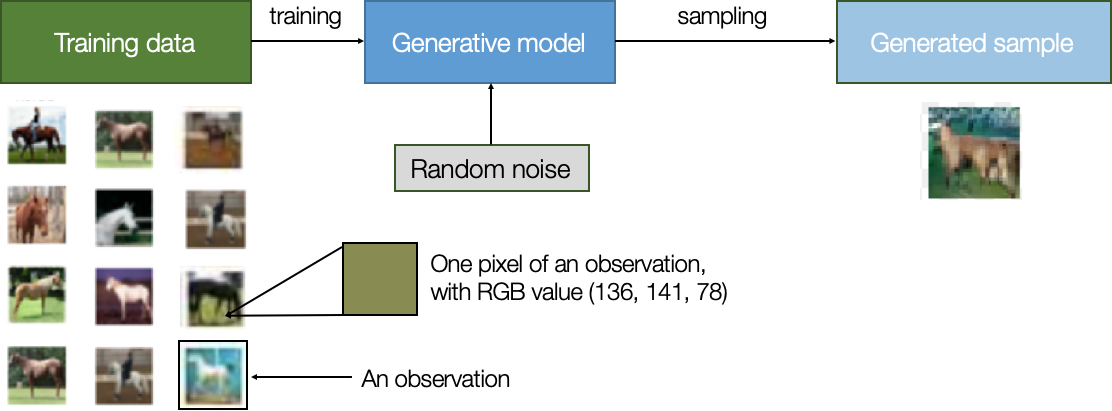
Each observation has many characteristics (or features), e.g., each pixel value. The goal is to build a model that can generate new sets of features that look like they have been created using the same rules as the original data.
Algorithms
Generative models used to produce synthetic data may use a number of architectures. You may have heard of Generative Adversarial Networks, or GANs, which can be used to generate artificial images, videos, etc. (Heard of deep fakes?). The basic idea behind GANs is to pit two neural networks against each other: a generator tries to fool the discriminator by producing real-looking images while the discriminator tries to distinguish between real and fake images. The process ends when the discriminator can no longer discern.
Besides GANs, other architectures are used to produce synthetic data. For instance, Variational Autoencoders try to compress the data to a lower dimensional space and then reconstruct it back to the original. More methods include Restricted Boltzmann Machines, Bayesian networks, Markov random fields, Markov chain Monte Carlo methods, etc. (Btw did you know that ChatGPT is also a generative model?)
Note: Throughout the post, I somewhat abuse the term “generative models.” While all the synthetic data techniques we consider use machine learning models (they train a model to learn the dataset distribution), some are not technically generative models. Please let this one slide ☺️
What Can Synthetic Data Be Used For?
Let’s start with how companies market their synthetic data technologies in this space, looking at material by Datagen.tech, Mostly.ai, Hazy.com, Gretel.ai, and Aindo.com. They mention several use cases, including:
1) Training Machine Learning Models: synthetic data can be used to augment real data, upsample/rebalance under-represented classes, or make models more robust to special events, e.g., in the context of fraud detection, healthcare, etc.
2) Product and Software Testing: generating synthetic test data can be easier than obtaining real rule-based test data to provide “flexibility, scalability, and realism” during testing. For example, companies often can’t legally use production data for testing purposes.
3) Governance: synthetic data can help remove biases, stress-test models, and increase explainability.
4) Privacy: synthetic data can mitigate privacy concerns when sharing or using data across and within organizations. Datasets are considered “anonymous,” “safe,” or void of personally identifiable information. This allows data scientists to comply with data protection regulations like HIPAA, GDPR, CCPA, etc.
Overall, over the past few years, there have been several initiatives and efforts both in industry and government. For example, the UK’s National Health Service piloted a project to release synthetic data from “A&E” (i.e., Emergency Room) activity data and admitted patient care. In 2018 and 2020, the US National Institute of Standards and Technology (NIST) ran two challenges related to synthetic data: the Differential Privacy Synthetic Data and Temporal Map challenges, awarding cash prizes seeking innovative synthetic data algorithms and metrics.
Risks of Using Synthetic Data
To reason around the risks of synthetic data, researchers have used a few “metrics” to measure privacy properties.
Linkage
Because synthetic data is “artificial,” a common argument is that there is no direct link between real and synthetic records, unlike anonymized records. Thus, researchers have used similarity tests between real and synthetic records to support the safety of synthetic data. Unfortunately, however, this kind of metric fails to grasp the real risks of a strategic adversary using features that are likely to be influenced by the target’s presence.Attribute Disclosure
This kind of privacy violation happens whenever access to data allows an attacker to learn new information about a specific individual, e.g., the value of a particular attribute like race, age, income, etc. Unfortunately, if the real data contains strong correlations between attributes, these correlations will likely be replicated in the synthetic data and available to the adversary. Furthermore, Theresa Stadler et al. show that records with rare attributes or whose presence affects the ranges of numerical attributes remain highly vulnerable to disclosure.Attacks
Roughly speaking, linkage is often formulated as a successful membership inference attack. Here an adversary aims to infer if the data from specific target individuals were relied upon by the synthetic data generation process: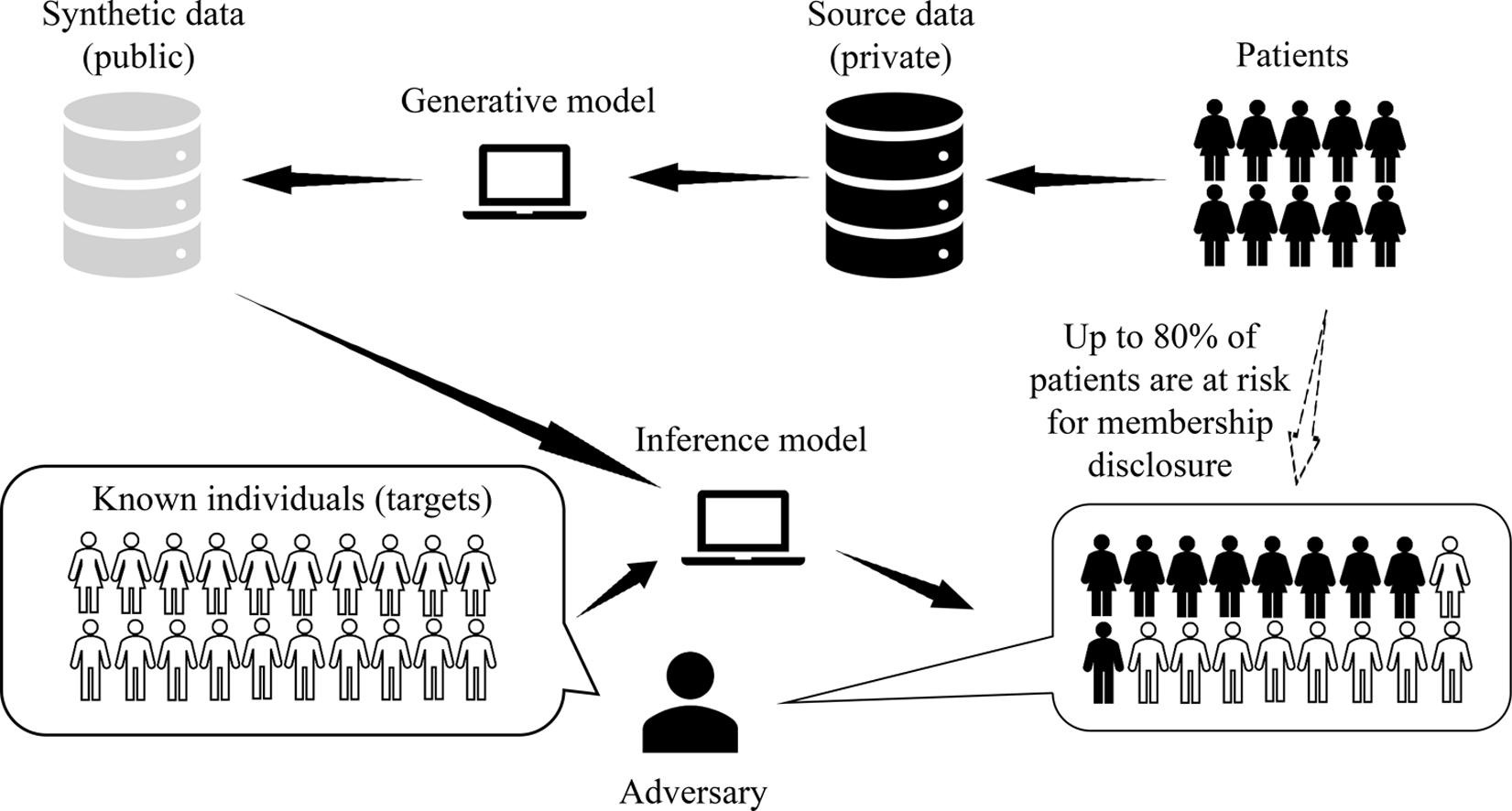
Consider the example in the figure above where synthetic health images are used for research: discovering that a specific record was used in a study leaks information about the individual’s health.
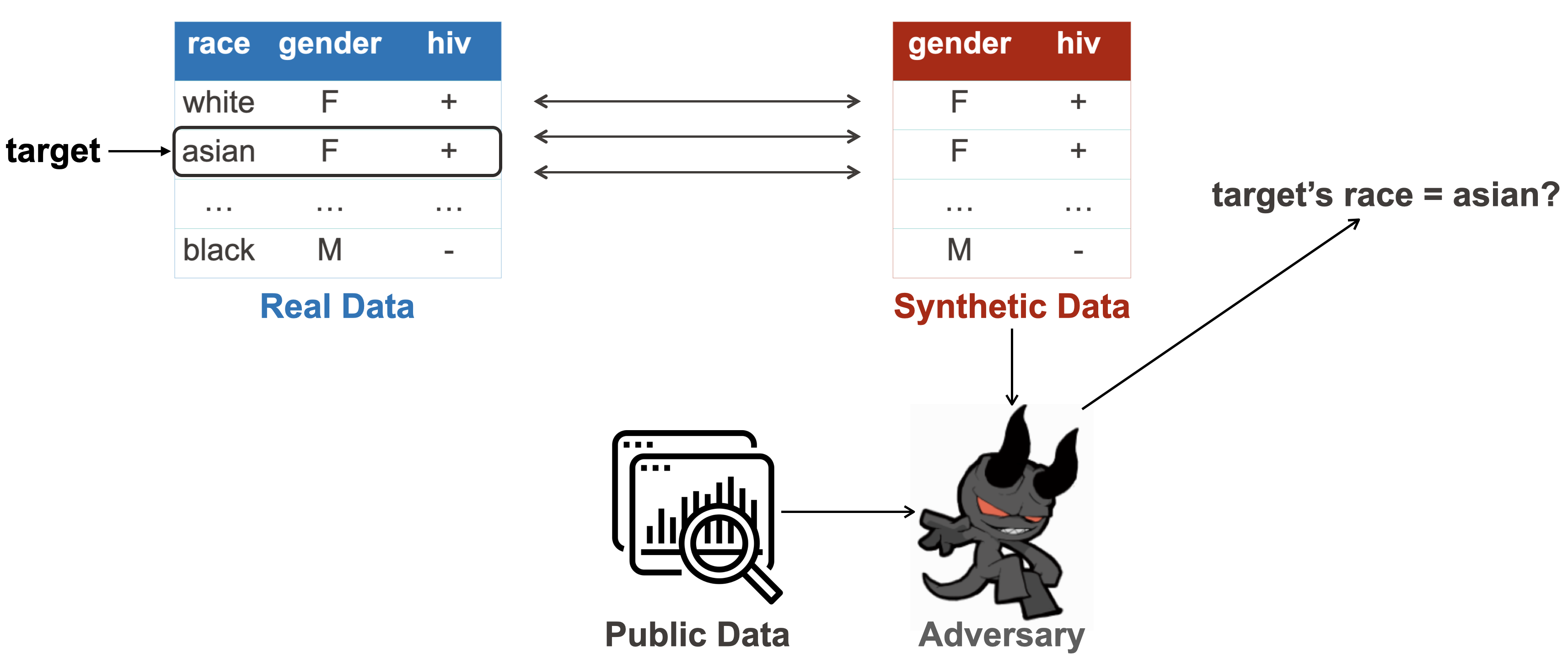
Attribute disclosure is usually formulated as an attribute/property inference attack. Here, the adversary, given some public information of some users, tries to reconstruct some private attributes of some target users.
How realistic are the attacks?
One important thing to understand about most privacy studies is that they do not provide “binary” answers, e.g., telling us that some method either provides perfect privacy or none at all. Instead, they provide probability distributions vis-à-vis different systems/threat models, adversarial assumptions, datasets, etc. However, the picture is quite bleak, with a significant number of gaps identified by state-of-the-art research studies. A good example in this direction is the recent research paper “Synthetic Data – Anonymisation Groundhog Day,” which shows that, in practice, synthetic data provides little additional protection compared to anonymization techniques, with privacy-utility trade-offs being even harder to predict.Enter Differential Privacy
Is there anything we can do to increase the privacy protection of synthetic data? The state-of-the-art method for providing access to information free from inferences is to satisfy differential privacy. Generally speaking, differential privacy provides mathematical guarantees against what an adversary can infer from learning the result of some algorithm. In other words, it guarantees that an individual will be exposed to the same privacy risk whether or not her data is included in a differentially private analysis.Overall, differential privacy is generally achieved by adding noise at various steps. In the context of synthetic data, the idea is to train the generative models used to produce synthetic data in a differentially private manner. Typically, one of three methods is used: using the Laplace mechanism, sanitizing the gradients during stochastic gradient descent, or using a technique called PATE. The resulting methods tend to combine generative model architectures with differential privacy; state-of-the-art tools include DP-GAN, DP-WGAN, DP-Syn, PrivBayes, PATE-GAN, etc. A list of relevant papers (with code) is available on Georgi Ganev’s GitHub.
The Inherent Limitations
As a privacy researcher, my focus on the limitations of synthetic data is mainly on its security and privacy shortcomings. There likely are other challenges, e.g., regarding usability, fidelity, and interpretability, but I leave it to my more qualified colleagues to chime in.
When it comes to privacy, it is unlikely that synthetic data will provide a silver bullet to sanitize sensitive data or safely share confidential information across the board. Instead, there could be specific use cases where training a generative model provides better flexibility and privacy protection than the alternatives. For instance, financial companies can use synthetic data to ensure production data is not used during testing or shared across different sub-organizations. Or perhaps governmental agencies could enable citizens and entities to extract high-level statistics from certain data distributions without doing it themselves.
But those case studies are arguably not going to generalize. Put simply, generative models trained without differential privacy (or with very large privacy budgets) do not provide high safety, privacy, or confidentiality levels. Conversely, differential privacy can but with a non-negligible cost to utility/accuracy. More precisely, protecting privacy inherently means you must “hide” vulnerable data points like outliers, etc. So if you want to use synthetic data to upsample an under-represented class, train a fraud/anomaly detection model, etc., you will have either privacy or utility.
Another limitation is that usable privacy mechanisms must be predictable, i.e., building on a good understanding of how data will be handled and protected. That’s not always the case with synthetic data, because of the probabilistic nature of generative models and the inherent difficulty of predicting what signals a synthetic dataset will preserve and what information will be lost.
Looking Ahead
There are several interesting open research questions in this field. For instance, the differential privacy framework often provides an overly conservative approach to privacy. This is for good measure, as we want a worst-case definition that is as agnostic as possible to any adversarial assumption. But in practice, the accuracy of the attacks we can realistically implement is measurably far from the theoretical bounds.
The privacy engineering community can help practitioners and stakeholders identify the use cases where synthetic data can be used safely, perhaps even in a semi-automated way. At the very least, the research community can provide actionable guidelines to understand the distributions, types of data, tasks, etc. where we could achieve reasonable privacy-utility tradeoffs via synthetic data produced by generative models.
Acknowledgements
Many thanks to Georgi Ganev, Bristena Oprisanu, and Meenatchi Sundaram Muthu Selva Annamalai for reviewing a draft of this article.