Selective disclosure credentials allow the issuance of a credential to a user, and the subsequent unlinkable revelation (or ‘showing’) of some of the attributes it encodes to a verifier for the purposes of authentication, authorisation or to implement electronic cash. While a number of schemes have been proposed, these have limitations, particularly when it comes to issuing fully functional selective disclosure credentials without sacrificing desirable distributed trust assumptions. Some entrust a single issuer with the credential signature key, allowing a malicious issuer to forge any credential or electronic coin. Other schemes do not provide the necessary re-randomisation or blind issuing properties necessary to implement modern selective disclosure credentials. No existing scheme provides all of threshold distributed issuance, private attributes, re-randomisation, and unlinkable multi-show selective disclosure.
We address these challenges in our new work Coconut – a novel scheme that supports distributed threshold issuance, public and private attributes, re-randomization, and multiple unlinkable selective attribute revelations. Coconut allows a subset of decentralised mutually distrustful authorities to jointly issue credentials, on public or private attributes. These credentials cannot be forged by users, or any small subset of potentially corrupt authorities. Credentials can be re-randomised before selected attributes being shown to a verifier, protecting privacy even in the case all authorities and verifiers collude.
Applications to Smart Contracts
The lack of full-featured selective disclosure credentials impacts platforms that support ‘smart contracts’, such as Ethereum, Hyperledger and Chainspace. They all share the limitation that verifiable smart contracts may only perform operations recorded on a public blockchain. Moreover, the security models of these systems generally assume that integrity should hold in the presence of a threshold number of dishonest or faulty nodes (Byzantine fault tolerance). It is desirable for similar assumptions to hold for multiple credential issuers (threshold aggregability). Issuing credentials through smart contracts would be very useful. A smart contract could conditionally issue user credentials depending on the state of the blockchain, or attest some claim about a user operating through the contract—such as their identity, attributes, or even the balance of their wallet.
As Coconut is based on a threshold issuance signature scheme, that allows partial claims to be aggregated into a single credential, it allows collections of authorities in charge of maintaining a blockchain, or a side chain based on a federated peg, to jointly issue selective disclosure credentials.
System Overview
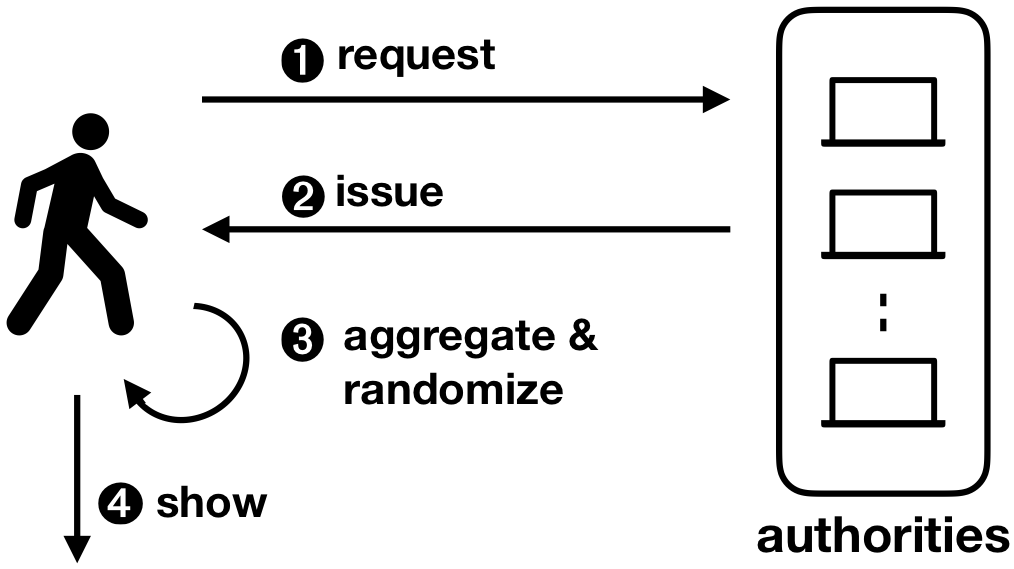
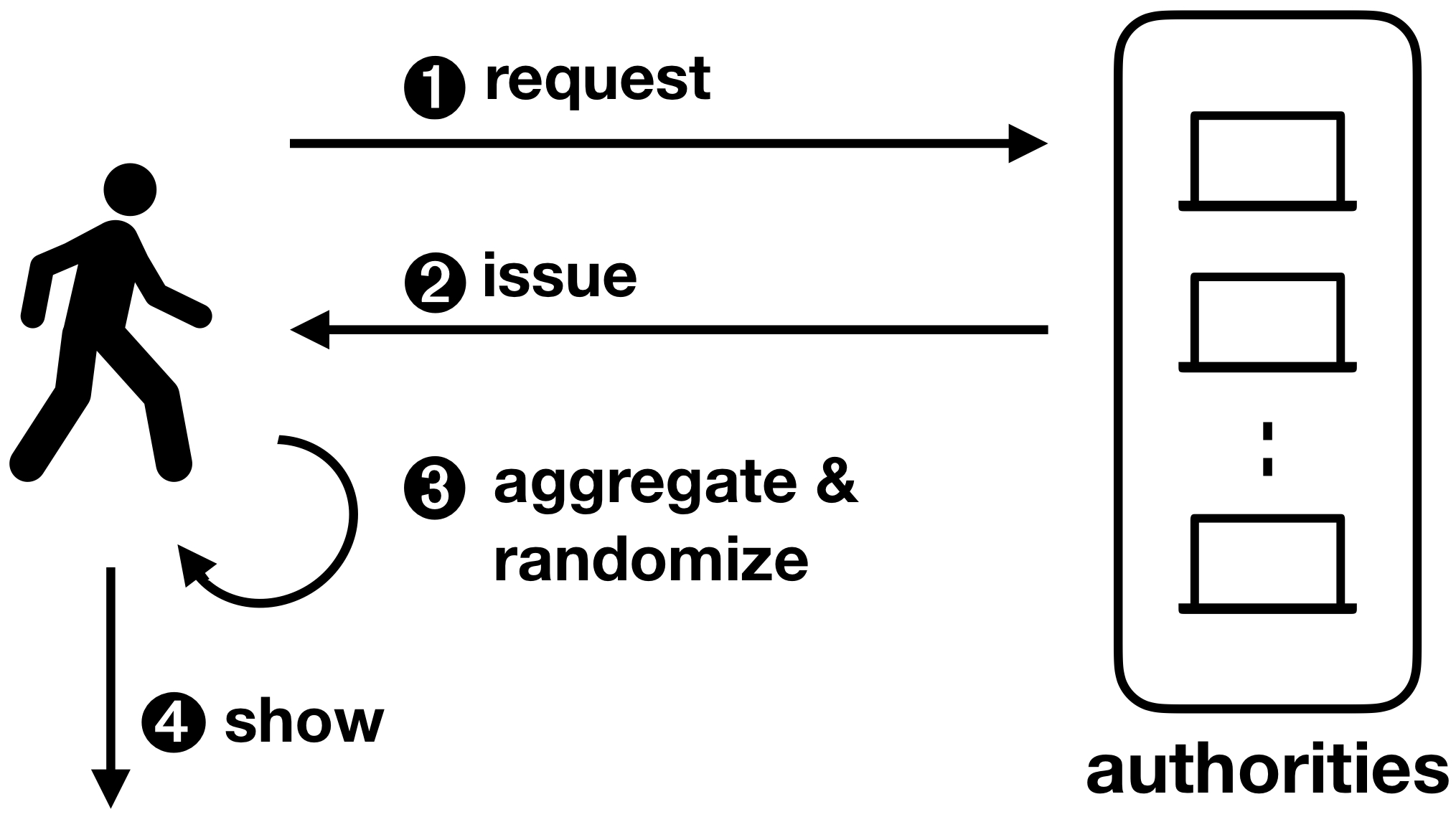
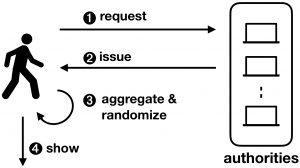
Coconut is a fully featured selective disclosure credential system, supporting threshold credential issuance of public and private attributes, re-randomisation of credentials to support multiple unlikable revelations, and the ability to selectively disclose a subset of attributes. It is embedded into a smart contract library, that can be called from other contracts to issue credentials. The Coconut architecture is illustrated below. Any Coconut user may send a Coconut request command to a set of Coconut signing authorities; this command specifies a set of public or encrypted private attributes to be certified into the credential (1). Then, each authority answers with an issue command delivering a partial credentials (2). Any user can collect a threshold number of shares, aggregate them to form a consolidated credential, and re-randomise it (3). The use of the credential for authentication is however restricted to a user who knows the private attributes embedded in the credential—such as a private key. The user who owns the credentials can then execute the show protocol to selectively disclose attributes or statements about them (4). The showing protocol is publicly verifiable, and may be publicly recorded.
Implementation
We use Coconut to implement a generic smart contract library for Chainspace and one for Ethereum, performing public and private attribute issuing, aggregation, randomisation and selective disclosure. We evaluate their performance, and cost within those platforms. In addition, we design three applications using the Coconut contract library: a coin tumbler providing payment anonymity, a privacy preserving electronic petitions, and a proxy distribution system for a censorship resistance system. We implement and evaluate the first two former ones on the Chainspace platform, and provide a security and performance evaluation. We have released the Coconut white-paper, and the code is available as an open-source project on Github.
Performance
Coconut uses short and computationally efficient credentials, and efficient revelation of selected attributes and verification protocols. Each partial credentials and the consolidated credential is composed of exactly two group elements. The size of the credential remains constant, and the attribute showing and verification are O(1) in terms of both cryptographic computations and communication of cryptographic material – irrespective of the number of attributes or authorities/issuers. Our evaluation of the Coconut primitives shows very promising results. Verification takes about 10ms, while signing an attribute is 15 times faster. The latency is about 600 ms when the client aggregates partial credentials from 10 authorities distributed across the world.
Summary
Existing selective credential disclosure schemes do not provide the full set of desired properties needed to issue fully functional selective disclosure credentials without sacrificing desirable distributed trust assumptions. To fill this gap, we presented Coconut which enables selective disclosure credentials – an important privacy enhancing technology – to be embedded into modern transparent computation platforms. The paper includes an overview of the Coconut system, and the cryptographic primitives underlying Coconut; an implementation and evaluation of Coconut as a smart contract library in Chainspace and Ethereum, a sharded and a permissionless blockchain respectively; and three diverse and important application to anonymous payments, petitions and censorship resistance.
We have released the Coconut white-paper, and the code is available as an open-source project on GitHub. We would be happy to receive your feedback, thoughts, and suggestions about Coconut via comments on this blog post.
The Coconut project is developed, and funded, in the context of the EU H2020 Decode project, the EPSRC Glass Houses project and the Alan Turing Institute.