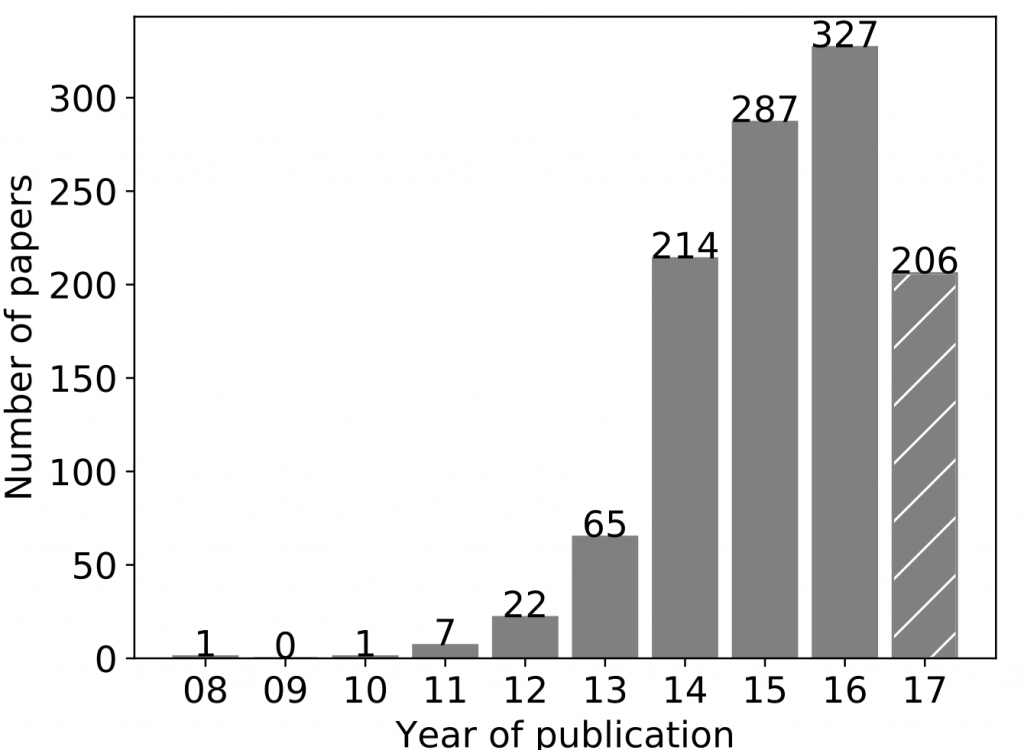
Internet services are suffering from various maladies ranging from algorithmic bias to misinformation and online propaganda. Could computer ethics be a remedy? Mozilla’s head Mitchell Baker warns that computer science education without ethics will lead the next generation of technologists to inherit the ethical blind spots of those currently in charge. A number of leaders in the tech industry have lent their support to Mozilla’s Responsible Computer Science Challenge initiative to integrate ethics with undergraduate computer science training. There is a heightened interest in the concept of ethical by design, the idea of baking ethical principles and human values into the software development process from design to deployment.
Ethical education and awareness are important, and there exist a number of useful relevant resources. Most computer science practitioners refer to the codes of ethics and conduct provided by the field’s professional bodies such as the Association for Computing Machinery and the Institute of Electrical and Electronics Engineers, and in the UK the British Computing Society and the Institute of Engineering and Technology. Computer science research is predominantly guided by the principles laid out in the Menlo Report.
But aspirations and reality often diverge, and ethical codes do not directly translate to ethical practice. Or the ethical practices of about five companies to be precise. The concentration of power among a small number of big companies means that their practices define the online experience of the majority of Internet users. I showed this amplified power in my study on the Web’s differential treatment of the users of Tor anonymity network.
Ethical code alone is not enough and needs to be complemented by suitable enforcement and reinforcement. So who will do the job? Currently, for the most part, companies themselves are the judge and jury in how their practices are regulated. This is not a great idea. The obvious misalignment of incentives is aptly captured in an Urdu proverb that means: “The horse and grass can never be friends”. Self-regulation by companies can result in inconsistent and potentially biased regulation patterns, and/or over-regulation to stay legally safe.
Continue reading Can Ethics Help Restore Internet Freedom and Safety?