Now making up 85% of mobile devices, Android smartphones have become profitable targets for cybercriminals, allowing them to bypass two factor authentication or steal sensitive information such as credit cards details or login credentials.
Smartphones have limited battery and memory available, therefore, the defences that can be deployed on them have limitations. For these reasons, malware detection is usually performed in a centralised fashion by Android market operators. As previous work and even recent news have shown, however, even Google Play Store is not able to detect all malicious apps; to make things even worse, there are countries in which Google Play Store is blocked. This forces users to resort to third party markets, which are usually performing less careful malware checks.
Previous malware detection studies focused on models based on permissions or on specific API calls. While the first method is prone to false positives, the latter needs constant retraining, because apps as well as the Android framework itself are constantly changing.
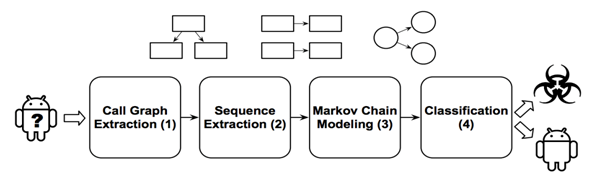
Our intuition is that, while malicious and benign apps may call the same API calls during their execution, the reason why those calls are made may be different, resulting in them being called in a different order. For this reason, we decided to rely on sequences of calls that, as explained later, we abstract to higher level for performance, feasibility, and robustness reasons. To implement this idea we created MaMaDroid, a system for Android malware detection.
MaMaDroid
MaMaDroid is built by combining four different phases:
- Call graph extraction: starting from the apk file of an app, we extract the call graph of the analysed sample.
- Sequence extraction: from the call graph, we extract the different potential paths as sequences of API calls and abstract all those calls to higher levels.
- Markov Chain modelling: all the samples got their sequences of abstracted calls, and these sequences can be modelled as transitions among states of a Markov Chain.
- Classification: Given the probabilities of transition between states of the chains as features set, we apply machine learning to detect malicious apps.
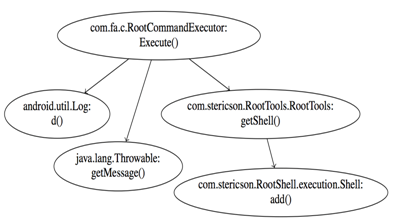
Call graph extraction
MaMaDroid is a system based only on static analysis. To analyse the app, we use off-the-shelf tools, such as Soot and FlowDroid for the first step of the system.
Sequence Extraction
Taking the call graph as input, we extract the sequences of functions potentially called by the program and, by identifying the set of entry nodes, enumerate all the possible paths and output them as sequences of API calls.
Continue reading MAMADROID: Detecting Android Malware by Building Markov Chains of Behavioral Models
{kind=link}