Now making up 85% of mobile devices, Android smartphones have become profitable targets for cybercriminals, allowing them to bypass two factor authentication or steal sensitive information such as credit cards details or login credentials.
Smartphones have limited battery and memory available, therefore, the defences that can be deployed on them have limitations. For these reasons, malware detection is usually performed in a centralised fashion by Android market operators. As previous work and even recent news have shown, however, even Google Play Store is not able to detect all malicious apps; to make things even worse, there are countries in which Google Play Store is blocked. This forces users to resort to third party markets, which are usually performing less careful malware checks.
Previous malware detection studies focused on models based on permissions or on specific API calls. While the first method is prone to false positives, the latter needs constant retraining, because apps as well as the Android framework itself are constantly changing.
Our intuition is that, while malicious and benign apps may call the same API calls during their execution, the reason why those calls are made may be different, resulting in them being called in a different order. For this reason, we decided to rely on sequences of calls that, as explained later, we abstract to higher level for performance, feasibility, and robustness reasons. To implement this idea we created MaMaDroid, a system for Android malware detection.
MaMaDroid
MaMaDroid is built by combining four different phases:
- Call graph extraction: starting from the apk file of an app, we extract the call graph of the analysed sample.
- Sequence extraction: from the call graph, we extract the different potential paths as sequences of API calls and abstract all those calls to higher levels.
- Markov Chain modelling: all the samples got their sequences of abstracted calls, and these sequences can be modelled as transitions among states of a Markov Chain.
- Classification: Given the probabilities of transition between states of the chains as features set, we apply machine learning to detect malicious apps.
Call graph extraction
MaMaDroid is a system based only on static analysis. To analyse the app, we use off-the-shelf tools, such as Soot and FlowDroid for the first step of the system.
Sequence Extraction
Taking the call graph as input, we extract the sequences of functions potentially called by the program and, by identifying the set of entry nodes, enumerate all the possible paths and output them as sequences of API calls.
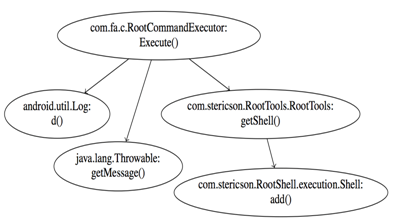
However, I specified that we would have used abstracted calls! The abstraction operation takes each API call, and throws away some information, while keeping only part of it. This is done because the number of calls involved is too high and, as shown later, by doing this detection is more resilient to changes in time.
We abstract to the packages level, as the packages are defined by Android developers, and to the families, that is an even more general division, taking into consideration only the first meaningful part of the API call (e.g. android, java, javax, etc.).
We used the 243 packages that are part of the Android system and 95 packages that are part of Google libraries. However, an app developer may write his own packages library and use them. If the method is clearly visible, these API calls are clustered as self-defined, while if there is identifier mangling, these calls are clustered as obfuscated. In the family abstraction, the families are only 9, plus self-defined and obfuscated clusters.
It is already possible to see that the two abstraction levels present two different levels of granularity, giving better granularity on one side and better performance (with regards to memory consumption and speed) on the other side.
Starting from the example graph above you can see the three paths that have the same first block (the root node of the previous figure).

Markov Chain modelling
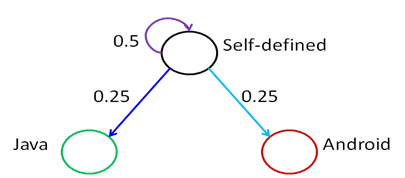
We used Markov Chains to model app behaviour, as they are a great tool to represent systems based on sequences of events as nodes and edges, representing states and transitions between a state and another one. These chains are memoryless, as the transitions probabilities from the current state to the next ones depend on the current state only. Each transition has a probability of transition associated to it and the sum of all the probabilities of the edges coming out from the same node has to be equal to one.
In our model each package/family is represented by a state. Given the sequences extracted previously we elaborate the probability of passing from one state to another. The set of these probabilities will form our feature set (as a vector). In package mode there are 340 states and, as a consequence, 115,600 possible transitions; in family mode there are only 11 states and, therefore, 121 possible transitions.
Below we enhance the crucial information needed for the Markov Chain for our example: the arrows indicate the transition between nodes, while the nodes (using family abstraction) are the circles highlighting the family of the call. Then you can find the Markov Chain of the example, using the same colours.

Classification
The classification phase uses Machine Learning algorithms; in particular, we tested the efficiency of Random Forests, 1-NN, 3-NN and SVM. The last one was discarded as it was slower and less accurate in classification than the other ones.
Datasets
To test MaMaDroid we used several datasets: two benign datasets and five malicious ones. The first benign dataset is taken from the PlayDrone one, with samples being a few years old. The second one is composed by the most popular apps in Google Play Store in March 2016, when all the experiments started. The malicious datasets have a classification that is year-based. The oldest is Drebin, a well-known malware dataset from a NDSS 2014 paper, which has samples from 2010 to 2012, the other ones are taken from VirusShare.com and are made by samples from years 2013, 2014, 2015, and 2016.
It was possible to study the evolution over time of the apps and we have observed that both benign and malicious apps are becoming more complicated in terms of API calls usage, with benign apps leading this evolution drift. Newest apps are using more API calls and, often, derived from a higher quantity of packages/families.
Evaluation
We used the F-Measure to evaluate our system through 3 different kinds of tests: testing on samples from the same databases of the training set, testing on newer samples than the ones used for the training set, and testing on older samples than the ones used for the training set.
The first series of tests highlighted how the classifiers are already reaching high F-measure scores when the families’ abstraction is in use (first pair of columns below), but the packages one is reaching even better scores (other columns), up to 0.99 and, on average, equal to 0.96 using Random Forests as classifier.
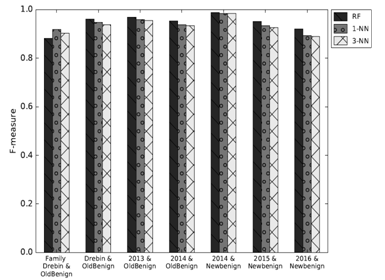
Testing on samples newer than the training ones (figure below, on the left) helps understanding if the system is resilient to changes in time, or if it needs constant retraining. In this section the families’ abstraction presents slightly better results, but both abstractions show really good results at least when there is one year of distance between training and test set and a fairly decent average score when this distance is increased by another year.
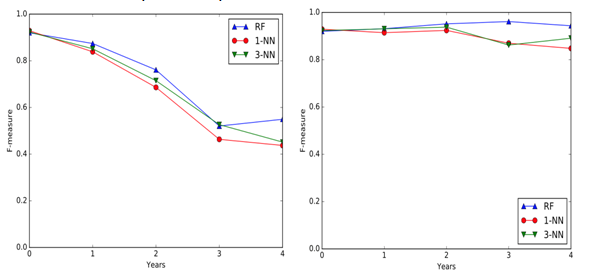
The last type of tests is useful to see if it is possible to identify old samples (figure above, on the right), without having to use other already existing techniques. The results are impressive using both abstractions; in fact, the average of the Random Forests classifier F-Measure remains constant over 0.9.
We compared on the same tests with another system already present in the literature, DroidAPIMiner, showing that our system performs better than this previous work.
Discussion
The first question one could raise is about the misclassification reported by MaMaDroid. To investigate this further, we analysed the false positives and the false negatives of the most interesting case: the classification using the 2016 malicious dataset and the new benign dataset. We observed that the reported false positives are mostly benign apps requiring dangerous permissions and using calls related to them without really needing them (such as the Emergency app using SMS related API calls). The false negatives were mostly composed by adware (that some researchers even do not categorise as malware, but potentially unwanted apps), as the ones repackaging only the advertisements library would not change the structure and the sequences of the API calls of the benign app that has been repackaged.
MaMaDroid might be evaded through repackaging benign apps, depending on how much the Markov Chain changes, while it is probably ineffective to add benign code from a goodware to a malicious app. It might be possible to imitate the Markov Chain of a benign app to evade the system; however, the point is if it is still possible to do something malicious by using always the same packages of a benign app.
There are limitations to the system, due to the fact that Soot crashed a few times, losing about the 4% of the samples, as well as to the memory allocation needed to classify with a fine grained abstraction. Obviously, as MaMaDroid uses only static analysis at the moment, it has the typical issues due to static analysis as, for instance, considering all the paths, also those that cannot be followed when running the app.
In the future we plan to work on exploring and testing in deep MaMaDroid’s resilience to the main evasion techniques, to try more fine-grained abstractions and seed with dynamic analysis.
The list of the used samples and the parsed dataset are already available under request, while the system code will be available soon.
Full details can be found in our paper, presented at the Network and Distributed Systems Symposium (NDSS) – MaMaDroid: Detecting Android Malware by Building Markov Chains of Behavioral Models – by Enrico Mariconti, Lucky Onwuzurike, Panagiotis Andriotis, Emiliano De Cristofaro, Gordon Ross, Gianluca Stringhini.
Really good layman explanation!
Can you please suggest the order of execution of the files provided for running MaMaDroid at https://bitbucket.org/gianluca_students/mamadroid_code
?