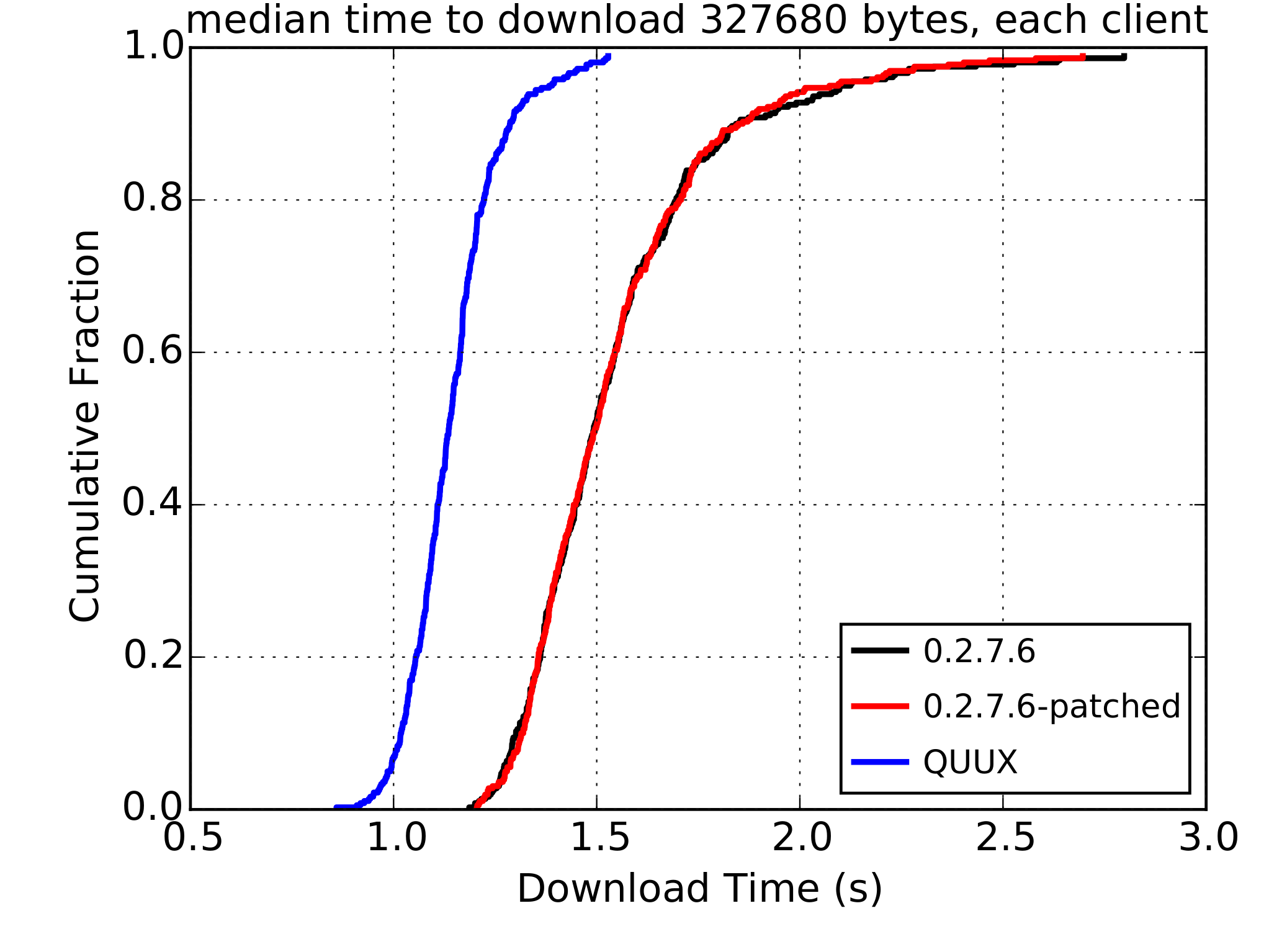
The vast majority of websites now support encrypted connections over HTTPS. This prevents eavesdroppers from monitoring or tampering with people’s web activity and is great for privacy. However, HTTPS is optional, and all browsers still support plain unsecured HTTP for when a website doesn’t support encryption. HTTP is commonly the default, and even when it’s not, there’s often no warning when access to a site falls back to using HTTP.
The optional nature of HTTPS is its weakness and can be exploited through tools, like sslstrip, which force browsers to fall back to HTTP, allowing the attacker to eavesdrop or tamper with the connection. In response to this weakness, HTTP Strict Transport Security (HSTS) was created. HSTS allows a website to tell the browser that only HTTPS should be used in future. As long as someone visits an HSTS-enabled website one time over a trustworthy Internet connection, their browser will refuse any attempt to fall back to HTTP. If that person then uses a malicious Internet connection, the worst that can happen is access to that website will be blocked; tampering and eavesdropping are prevented.
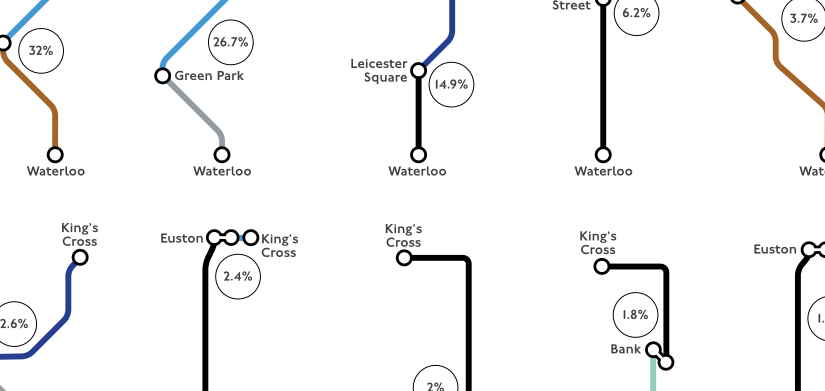
Still, someone needs to visit the website once before an HSTS setting is recorded, leaving a window of opportunity for an attacker. The sooner a website can get its HSTS setting recorded, the better. One aspect of HSTS that helps is that a website can indicate that not only should it be HSTS enabled, but that all subdomains are too. For example, planet.wikimedia.org can say that the subdomain en.planet.wikimedia.org is HSTS enabled. However, planet.wikimedia.org can’t say that commons.wikimedia.org is HSTS enabled because they are sibling domains. As a result, someone would need to visit both commons.wikimedia.org and planet.wikimedia.org before both websites would be protected.
What if HSTS could be applied to sibling domains and not just subdomains? That would allow one domain to protect accesses to another. The HSTS specification explicitly excludes this feature, for a good reason: discovering whether two sibling domains are run by the same organisation is fraught with difficulty. However, it turns out there’s a way to “trick” browsers into pre-loading HSTS status for sibling domains.
 Continue reading Pre-loading HSTS for sibling domains through this one weird trick
Continue reading Pre-loading HSTS for sibling domains through this one weird trick