Mobile developers are familiar with proximity sensors. These provide information about the distance of an object from the device providing access to the sensor (i.e. smartphone, tablet, laptop, or another Web of Things device). This object is usually the user’s head or hand.
Proximity sensors provide binary values such as far (from the object) or near (respectively), or a more verbose readout, in centimeters.
There are many useful applications for proximity. For example, an application can turn off the screen if the user holds the device close to his/her head (face detection). It is also handy for avoiding the execution of undesired actions, possibly arising from scratching the head with the phone’s screen.
The Proximity Sensor API specification is being standardized by W3C. Every web site will be able to access this information. Let’s focus on the privacy engineering point of view.
Proximity is the distance between an object and device. The latest version of W3C Proximity Sensors API takes advantage of a soon-to-be standard Generic Sensors API. The sensor provides the proximity distance in centimeters.
The use of Proximity Sensors is simple; an example displaying the current distance in centimeters using the modern syntax of Generic Sensors API is as follows:
let sensor = new ProximitySensor();
sensor.start();
sensor.onchange = function(){console.log(event.reading.distance)};
This syntax might later allow requesting various proximity sensors (if the device has more than one), including those based on the sensor’s position (such as “rear” or “front”), but the current implementations generally still use the legacy version from the previous edition of the spec:
window.addEventListener('deviceproximity', function(event) {
console.log(event.value)
});
From the perspective of privacy considerations, there is currently no significant difference between those two API versions.
Privacy analysis of Proximity Sensor API
Proximity sensor readout is not providing much data, so it may appear there are no privacy implications, but there are good reasons for performing such analysis. Let’s list two:
Firstly, designing new standards and systems with privacy in mind — privacy by design — is a required practice and a good idea. Secondly, in some circumstances even potentially insignificant mechanisms can still bring consequences from privacy point of view. For example, multiple identifiers might be helpful in deanonymizing users. Non-obvious data leaks can surface, as well.
So let’s discuss some of the possible issues.
The average distance from the device to the user’s face (i.e. object) could be used to differentiate and discriminate between users. While the severity is hard to establish, future changes (i.e. influencing with other external data) cannot be ruled out.
If proximity patterns would be individually-attributable, this would offer a possibility to enhance user profiling based on the analysis of device use patterns. For example, the following could be obtained and analyzed:
- Frequency of the user’s patterns of device use (i.e. waving a hand in front of the proximity sensor)
- Frequency of the user’s zooming in and out (i.e. device close to the user’s head)
- Patterns of use. Does the way the user hold the device vary during the day? How?
- What are the mechanics of holding the device close to the user’s head? Can the distance vary?
Some users may use the mobile operating system’s zoom capability to increase the font or images, but others might casually prefer to hold the device closer to their eyes. Such behavioral differences can also be of note.
Proximity sensors can provide the following data: the current proximity distance and max, the maximum distance readout supported by the device. In case the value of max would differ between various implementations (e.g. among browsers, devices), it could form an identifier. And the two (max, distance) combined could also be used as short-lived identifiers. Moreover, it is not so difficult to imagine a situation where those identifiers are actually not so short-lived.
Recommendations
First of all, is there a need to provide a verbose proximity readout at all? For example, is providing readouts of proximity (distance) value up to 150 cm necessary?
In general, a device (browser, a Web of Things device) should be capable of informing the user when a web site accesses proximity information. The user should also be able to inspect which web sites – and how frequently – accessed the API.
Finally, the sensors should provide an adequately verbose readout of the distance.
Proximity Sensors should also be subject to permissions.
Demonstration
At the moment, the implementations of proximity sensors are limited. But a demonstration is running on my SensorsPrivacy research project (tested against Firefox Mobile on Android). In my case (Nexus 5), Firefox offered data in centimeters, but the verbosity was limited to 5 centimeters on my device. Again, this is a matter of hardware and software. In principle, the accuracy could be much higher and one can imagine an accuracy a sensor providing more accurate readouts (even up to 1 meter).
The screen dump below shows how the example demonstrates the use of proximity data (and whether it works on a browser). The site changes its background color if an object is placed near the proximity sensor of a device.
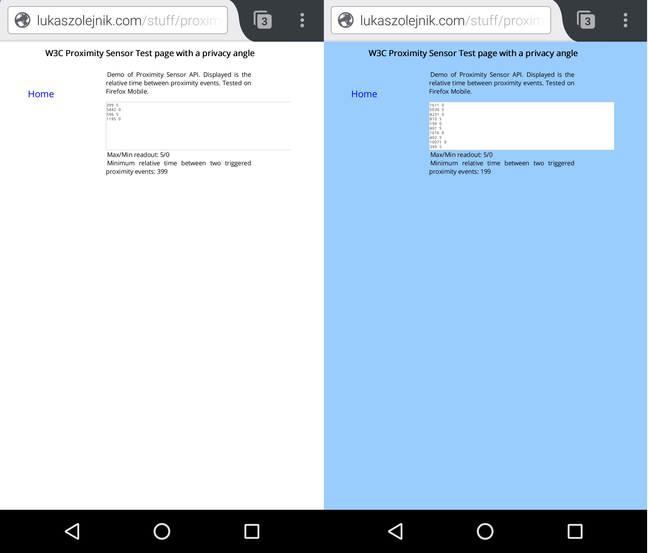
The readout from the demonstration shows a relative time between events (first column), and the proximity distance (second column).
The sensor on my device is reporting two values of distance: 0 (near) and 5 (far), in centimeters. In general, the granularity is subject to the following: standard, implementation and hardware.
And this suggests something, of course. So let’s complement the privacy analysis from the previous section to incorporate a timing analysis.
Even such a limited readout can help performing behavioural analysis, simply by profiling based on time series. As we can see, the sensor readout is quite sensitive in respect to time and can measure with sub-200 ms granularity. The demonstration proof of principle is also showing the minimum relative detected time between events. Feel free to test the performance of your fingers and/or hardware!
Summary
When designing a standard project or an implementation, paying attention to details is imperative. This includes consideration of even potential risks. This is especially the case if the software or systems will be used by millions or hundreds of millions of users, i.e. you are aiming for success.
Finally, standards and specifications are ideal for issuing guidance and good practices
This post originally appeared on Security, Privacy & Tech Inquiries, the blog of Lukasz Olejnik. An accompanying demonstration is available on SensorsPrivacy (a project studing privacy of web sensors).