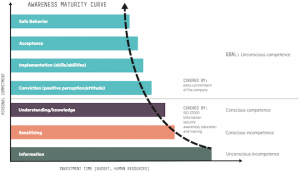
Yesterday, the Royal Society published their report on cybersecurity policy, practice and research – Progress and Research in Cybersecurity: Supporting a Resilient and Trustworthy System for the UK. The report includes 10 recommendations for government, industry, universities and research funders, covering the topics of trust, resilience, research and translation. This major report was written based on evidence gathered from an open call, as well as meetings with key stakeholders, guided by a steering committee which included UCL members M. Angela Sasse and Steven Murdoch. Here, we summarise what we think are the most important signposts for cybersecurity research and practice.
The report points out that, as online technology and services touches nearly everyone’s lives, the role of cybersecurity is to support a resilient digital economy and society in the UK. Previously, the government focus was very much on national security – but it is just as important that we are able to secure our personal data, financial assets and homes, and that our decisions as consumers and citizens are not manipulated or subverted. The report rightly states that the national authority for cybersecurity needs to be transparent, expert and have a clear and widely-understood remit. The creation of the National Cyber Security Center (NCSC) may be a first step towards this, but the report also points out that currently, it is to be under control of GCHQ – and this is bound to be a problem given the lack of trust they have from parts of industry and civil society, as a result of their role in subverting the development of security standards in order to make surveillance easier.
The report furthermore recommends that the government preserves the robustness of encryption, including end-to-end encryption and promotes its widespread use. Encryption and other computer security measures provides the foundation that allows individuals to trust organisations and attempts to weaken these measures in order to facilitate surveillance will create security risks and reduce robustness. Whether weaknesses are created by requiring fragile encryption algorithms or mandating exceptional access, these attempts increase the risk of unauthorised parties gaining access to sensitive computer systems.
The report also rightly says that companies need to take more responsibility for cyber security: to be a trustworthy business partner or service provider, they need to be competent, and have the correct motivation. “Dumping” the risks associated with online transactions on customers or business partners who don’t have skills and resources to deal with them, and hiding this in complex terms and conditions, is not trustworthy behaviour. Making companies take liability for the security failures will likely play a part in improving trustworthiness, but needs to be done carefully. Important open source software such as OpenSSL is developed by a handful of people in their spare time. When something goes wrong (such as Heartbleed), multi-billion dollar companies who built their business around open source software without contributing or even properly evaluating the risk, should not be able to assign liability to the volunteer developers. Companies should also be transparent and be required to disclose vulnerabilities and breaches. The report calls for such disclosures to be made to a central body, but we would go further and recommend that they be disclosed to the customers exposed to risks as a result of the security failures.
In order to improve and demonstrate competence in cybersecurity, we need evidence-based guidance on state-of-the-art cybersecurity principles, standards and practices. These go further than just following widely used industry practice, or following craft knowledge based on expert opinion, but should be an an ambitious set of criteria which have been demonstrated to make a pronounced improvement in security. A significant effort is required to transform what is currently a set of common practices (the term “best practice” is a misnomer) through empirical tests and measurements into a set of practices and tools that we know to be effective and efficient under real-world conditions (this is the mission of The Research Institute in Science of Cyber Security (RISCS), which has just started a new 5 year phase). The report in particular calls for research on ways to quantify the security offered by anonymization algorithms and anonymous communication techniques, as these perform an critical role in supporting privacy by design.
The report calls for more research, and new means to assess and support research. Cybersecurity is an international field, and research funders should seek for peer-review to be performed by the best expertise available internationally and to remove barriers to international and multidisciplinary research. However, supporting multidisciplinary research should not be at the expense of addressing the many hard technical problems which remain. The report also identifies the benefits of challenge-led funding, where a research programme is led by a world-leading expert with substantial freedom in how research funds are distributed. For this model to work it is critical to create the right environment for recruiting international experts to both lead and participate in such challenges, which as fellow steering-group member Ross Anderson has pointed out, the vote to leave the EU has seriously harmed. Finally, the report calls for improvements to the research commercialisation process, including that universities priorities getting research out into the real world over trying to extract as much money as possible, and that new investment sources are developed to fill in the gaps left by traditional venture capital, such as for software developed for the public good.