Within the European Union, since 2007, banks are regulated by the Payment Services Directive. This directive sets out which types of institutions can offer payment services, and what rules they must follow. Importantly for customers, these rules include in what circumstances a fraud victim is entitled to a refund. In 2015 the European Parliament adopted a substantial revision to the directive, the Payment Services Directive 2 (PSD2), and it will soon be implemented by EU member states. One of the major changes in PSD2 is the requirement for banks to implement Strong Customer Authentication (SCA) for transactions, more commonly known as two-factor authentication – authentication codes based on two or more elements selected from something only the user knows, something only the user possesses, and something the user is. Moreover, the authentication codes must be linked to the recipient and amount of the transaction, which the customer must be made aware of.
The PSD2 does not detail the requirements of Strong Customer Authentication, nor the permitted exemptions to this rule. Instead, these decisions are to be made by the European Banking Authority (EBA) through Regulatory Technical Standards (RTS). As part of the development of these technical standards the EBA opened an initial discussion, to which we submitted a response based on our research on the security usability of banking authentication. Based on the discussion, the EBA produced a consultation paper incorporating a set of draft technical standards. In our response to this consultation paper, included below, we detailed how research both on security usability and banking authentication more broadly should guide the assessment of Strong Customer Authentication. Specifically we point out that there is an incorrect assumption of an inherent tradeoff between security and usability, that for a system to be secure it must be usable, and that evaluation of Strong Customer Authentication systems should be independent, transparent, and follow principles developed from latest research.
False trade-off between security and usability
In the reasoning presented in the consultation paper there is an assumption that a trade-off must be made between security and usability, e.g. paragraph 6 “Finally, the objective of ensuring a high degree of security and safety would suggest that the [European Banking Authority’s] Technical Standards should be onerous in terms of authentication, whereas the objective of user-friendliness would suggest that the [Regulatory Technical Standards] should rather promote the competing aim of customer convenience, such as one-click payments.”
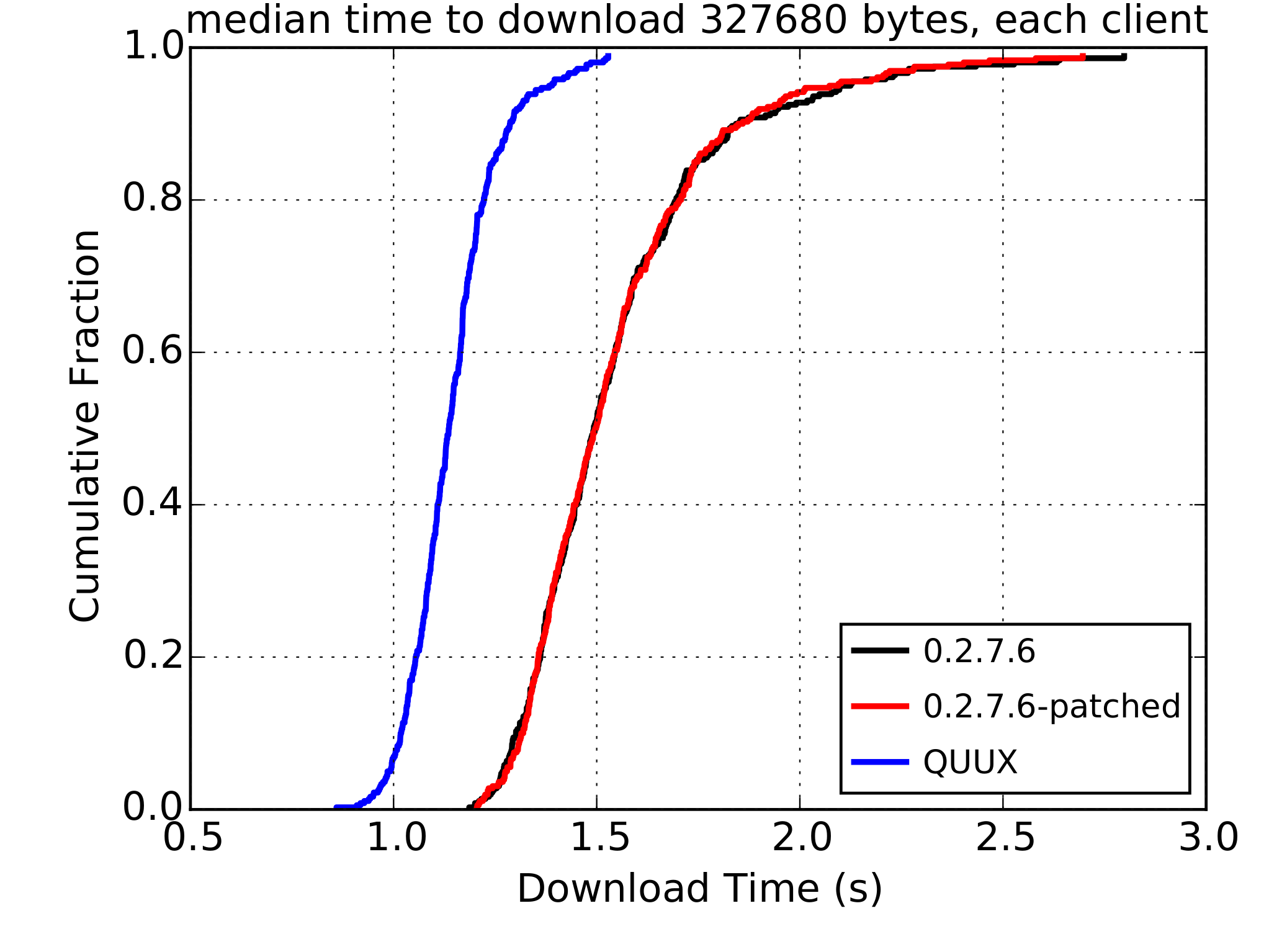
This security/usability trade-off is not inherent to Strong Customer Authentication (SCA), and in fact the opposite is more commonly true: in order for SCA to be secure it must also be usable “because if the security is usable, users will do the security tasks, rather than ignore or circumvent them”. Also, SCA that is usable will make it more likely that customers will detect fraud because they will not have to expend their limited attention on just performing the actions required to make the SCA work. A small subset (10–15%) of participants in some studies reasoned that the fact that a security mechanism required a lot of effort from them meant it was secure. But that is a misconception that must not be used as an excuse for effortful authentication procedures.
Continue reading Strong Customer Authentication in the Payment Services Directive 2