Latency is a key factor in the usability of web browsing. This has added relevance in the context of anonymity systems such as Tor, because the anonymity property is strengthened by having a larger user-base.
Decreasing the latency of typical web requests in Tor could encourage a wider user base, making it more viable for typical users who value their privacy and less conspicuous for the people who most need it. With this in mind for my MSc Information Security project at UCL, supervised by Dr Steven J. Murdoch, I looked at the transport subsystem used by the Tor network, hoping to improve its performance.
After a literature review of the area (several alternative transport designs have been proposed in the past), I started to doubt my initial mental model for an alternative design.
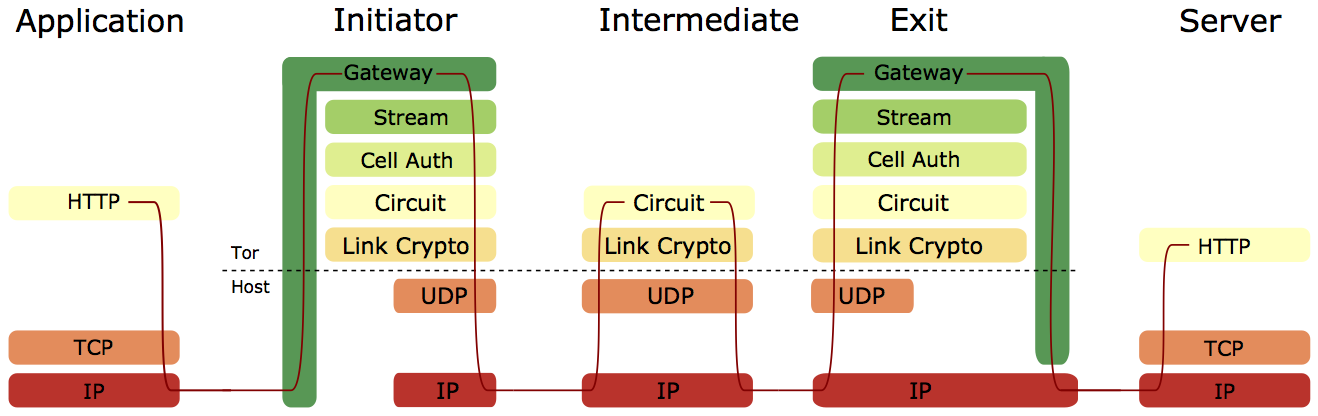
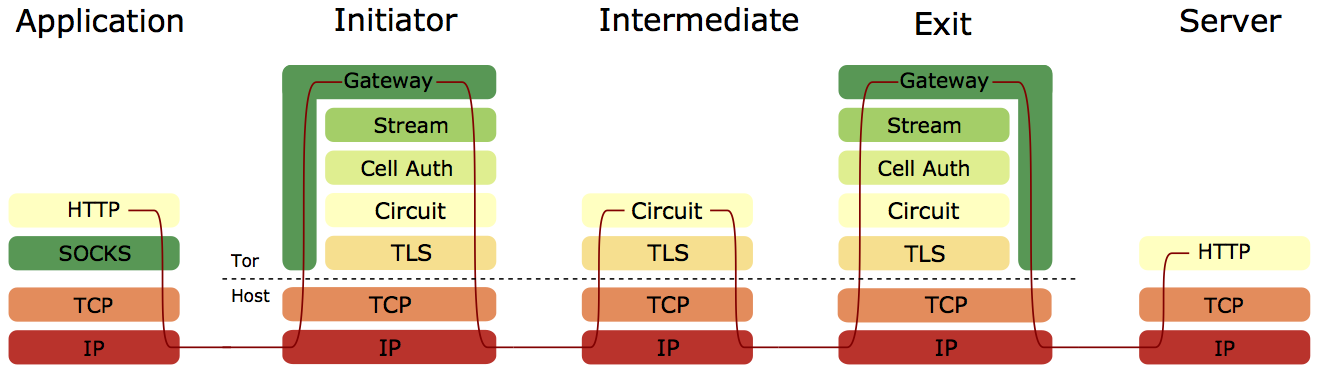
These diagrams show an end-to-end design (Freedom) and hop-by-hop design (Tor) respectively. In the end-to-end design, encrypted IP packets are transported between relays using UDP, with endpoints ensuring reliable delivery of packets. In the hop-by-hop design, TCP data is transported between relays, with relays ensuring reliable delivery of data.
The end-to-end Freedom approach seems elegant, with relays becoming somewhat closer to packet routers, however it also leads to longer TCP round-trip times (RTT) for web browser HTTP connections. Other things being equal, a longer TCP RTT will result in a slower transfer. Additional issues include difficulty in ensuring fairness of utilisation (requiring an approach outlined by Viecco), and potentially greater vulnerability to latency-based attack.
Therefore I opted to follow the hop-by-hop transport approach Tor currently takes. Tor multiplexes cells for different circuits over a single TCP connection between relay-pairs, and as a result a lost packet for one circuit could hold up all circuits that share the same connection (head-of-line blocking). A long-lived TCP connection is beneficial for converging on an optimal congestion window size, but the approach suffers from head-of-line blocking and doesn’t compete effectively with other TCP connections using the same link.
To remedy these issues, I made a branch of Tor which used a QUIC connection in place of the long-lived TCP connection. Because a QUIC connection carries multiple TCP-like streams, it doesn’t suffer from head-of-line blocking. The streams also compete for utilisation at the same level as TCP connections, allowing them to more effectively use either the link capacity or the relay-configured bandwidth limit.
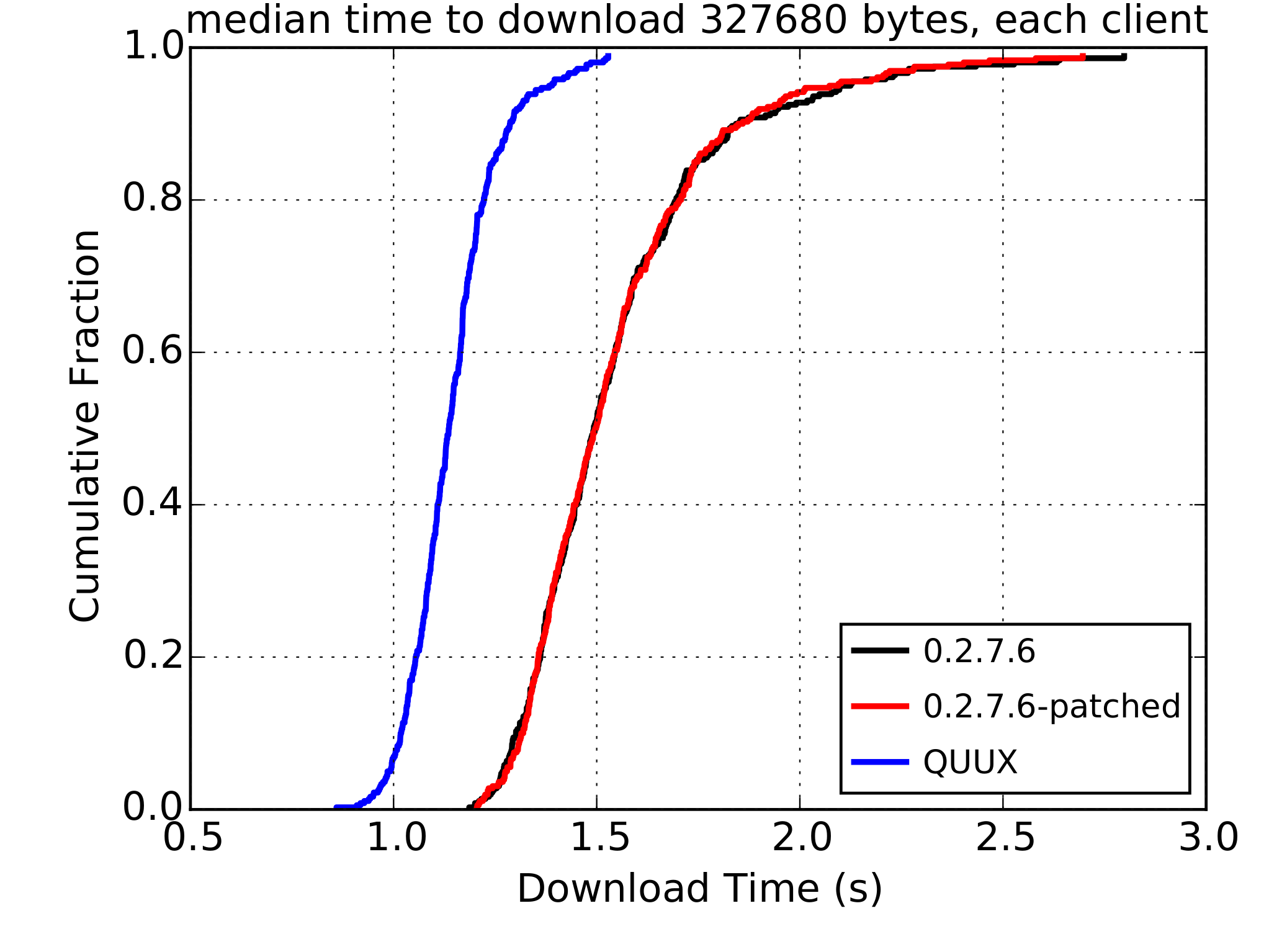
Initial results from the experiments are promising, as shown above. There’s still a way to go before such a design could make it into the Tor network. This branch shows the viability of the approach for performance, but significant engineering work still lies ahead to create a robust and secure implementation that would be suitable for deployment. There will also likely be further research to more accurately quantify the performance benefits of QUIC for Tor. Further details can be found in my MSc thesis.