Last week, Luca Melis has presented our NDSS16 paper “Efficient Private Statistics with Succinct Sketches“, where we show how to privately and efficiently aggregate data from many sources and/or large streams, and then use the aggregate to extract useful statistics and train simple machine learning models.
Our work is motivated by a few “real-world” problems:
- Media broadcasting providers like the BBC (with which we collaborate) routinely collect data from their users about videos they have watched (e.g., on BBC’s iPlayer) in order to provide users with personalized suggestions for other videos, based on recommender systems like Item k-Nearest Neighbor (ItemKNN)
- Urban and transport planning committees, such as London’s mass transport operators, need to gather statistics about people’s movements and commutes, e.g., to improve transportation services and predict near-future trends and anomalies on a short notice.
- Network infrastructures like the Tor network need to gather traffic statistics, like the number of, and traffic generated by, Tor hidden services, in order to tune design decisions as well as convince their founders the infrastructure is used for the intended purposes.
While different in their application, these examples exhibit a common feature: the need for providers to aggregate large amounts of sensitive information from large numbers of data sources, in order to produce aggregate statistics and possibly train machine learning models.
Prior work has proposed a few cryptographic tools for privacy-enhanced computation that could be use for private collection of statistics. For instance, by relying on homomorphic encryption and/or secret sharing, an untrusted aggregator can receive encrypted readings from users and only decrypt their sum. However, these require users to perform a number of cryptographic operations, and transmit a number of ciphertexts, linear in the size of their inputs, which makes it impractical for the scenarios discussed above, whereby inputs to be aggregated are quite large. For instance, if we use ItemKNN for the recommendations, we would need to aggregate values for “co-views” (i.e., videos that have been watched by the same user) of hundreds of videos at the time – thus, each user would have to encrypt and transfer hundreds of thousands of values at the time.
Scaling private aggregation
We tackle the problem from two points of view: an “algorithmic” one and a “system” one. That is, we have worked both on the design of the necessary cryptographic and data structure tools, as well as on making it easy for application developers to easily support these tools in web and mobile applications.
Our intuition is that, in many scenarios, it might be enough to collect estimates of statistics and trade off an upper-bounded error with significant efficiency gains. For instance, the accuracy of a recommender system might not be really affected if the statistics we need to train the model are approximated with a small error.
Therefore, we turn to efficient data structures, like Count-Min Sketches, which allow us to reduce storage, communication, and computational complexity of the underlying cryptographic protocols, from linear to logarithmic in the size of the inputs, while supporting count estimates with a parameterized upper-bound of the error. For instance, for the iPlayer’s recommender systems, we are able to dramatically reduce communication and computation complexities on the user-side (Figure 1) and on the server-side (Figure 2) without affecting accuracy (Figure 3).
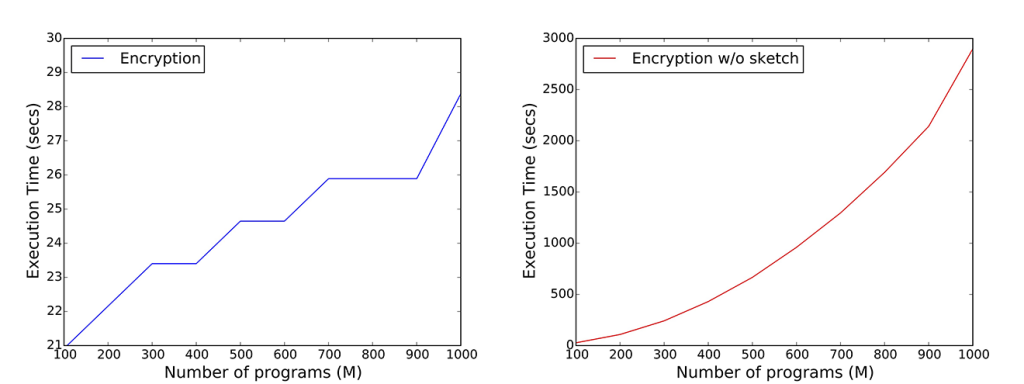
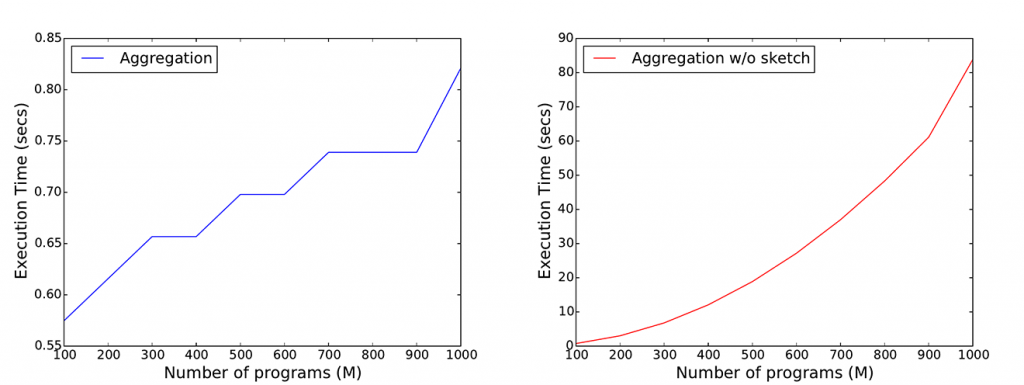
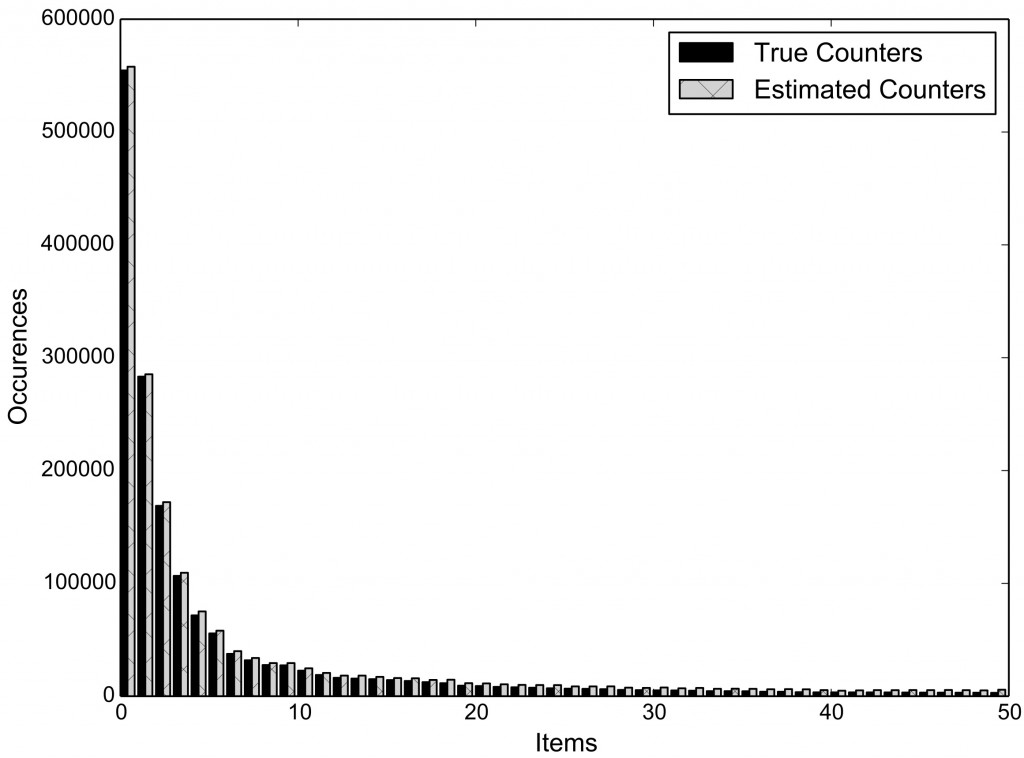
We have developed an open-source framework making it easy for application developers to support privately gathering statistics. We have implemented both the server-side and the client-side components of our protocols in both Python and JavaScript. While Python-based development allows us to integrate our tools in systems like Tor, developing in JavaScript enables to support the maximum compatibility across different platforms, including mobile ones, by means of tools like Node.js, Apache Cordova, and HTML5.
More specifically, all building blocks, including cryptographic, networking, and data processing layers, are available in a JavaScript module that application developers can import to easily deploy service providers on any given servers. The server-side module is developed as a Node.js module, so integrating it is as easy as installing a Node module through the Node Package Manager.
Finally, integration on the client-side will be transparent to the users (whose data will be aggregated) by embedding JavaScript code run from their web browsers or smartphones without the need to install additional software.
Privately collecting statistics on Tor hidden services
Next, we look at the importance of collecting statistics within the Tor network. The Tor project has recently received funding to improve monitoring of load and usage of Tor hidden services. This motivates them to extract aggregate statistics about the number of hidden service descriptors from multiple Hidden Service Directory authorities. In order to ensure robustness, the Tor project has determined that the median – rather than the mean – of these volumes should be calculated, which is beyond privacy-friendly statistics approaches like Privex.
For this problem, we need to use Count Sketches, which are similar to Count-Min Sketches but do not involve non-linear operations. We also need to protect output privacy, since our protocol leaks the volume of reported values falling within the intermediate ranges considered. To this end, we add differential privacy, specifically, using Laplace mechanism, however, having to trade-off between accuracy and privacy (Figure 4).
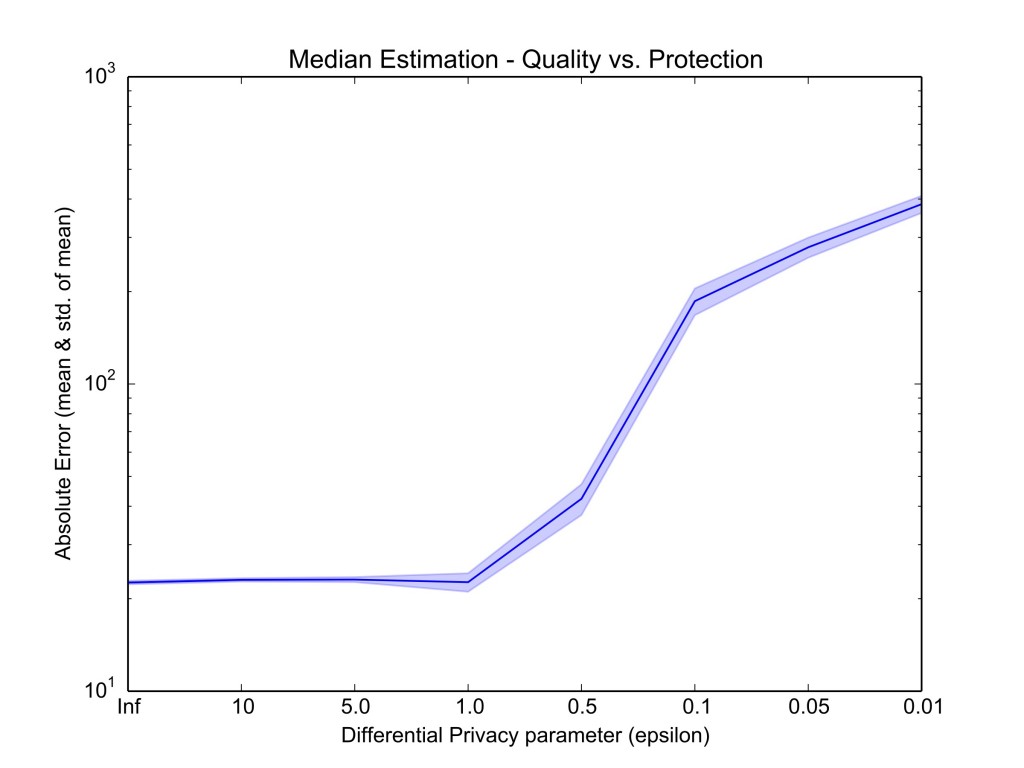
In conclusion, the techniques proposed in our work support different trust, robustness, and deployment models and can be applied to a number of interesting real-world problems where aggregate statistics can be used to train models. As part of future work, we are working on releasing a comprehensive framework supporting large-scale privacy-preserving aggregation as a service.