Recently I worked on some research with colleagues at Boston University (Manuel Egele, William Koch) and University College London (Gianluca Stringhini) into defeating ransomware. The fruit of our labor, PayBreak published this year in ACM ASIACCS, is a novel proactive system against ransomware. It happens to work against the new global ransomware threat, WannaCry. WannaCry is infecting more than 230,000 computers in 150 countries demanding ransom payments in exchange for access to precious files. This attack has been cited as being unprecidented, and the largest to date. Luckily, our research works against it.
PayBreak works by storing all the cryptographic material used during a ransomware attack. Modern ransomware uses what’s called a “hybrid cryptosystem”, meaning each ransomed file is encrypted using a different key, and each of those keys are then encrypted using another private key held by the ransomware authors. When ransomware attacks, PayBreak records the cryptographic keys used to encrypt each file, and securely stores them. When recovery is necessary, the victim retrieves the ransom keys, and iteratively decrypts each file.
Defeating WannaCry Ransomware
At this point, I think I’ve reverse engineered and researched something like 30 ransomware families, from over 1000 samples. Wannacry isn’t really much different than every other ransomware family. Those include other infamous families like Locky, CryptoWall, CryptoLocker, and TeslaLocker.
They all pretty much work the same way, including Wannacry. Actually, this comic sums up the ransom process the best I’ve seen. Every successful family today encrypts each file for ransom with a new unique “session” key, and encrypts each session key with a “private” ransom key. Those session keys are generated on the host machine. This is where PayBreak shims the generation, and usage of those keys, and saves them. Meaning, the encryption of those session keys by the ransomware’s private key is pointless, and defeated.
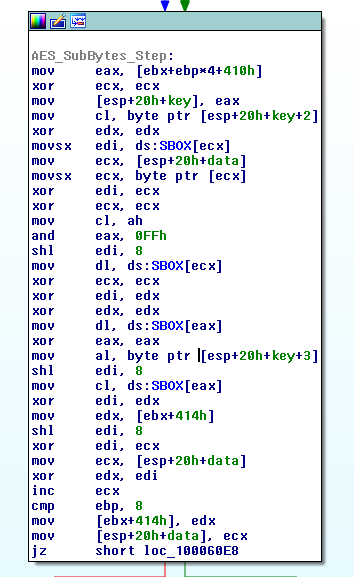
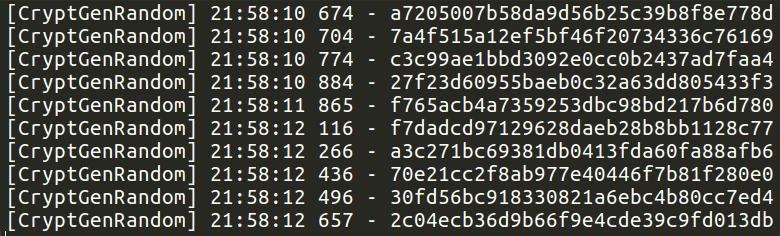
The PayBreak system doesn’t rely on any specific algorithm, or cryptographic library to be used by ransomware. Actually, Wannacry implemented, or atleast, statically compiled its own AES-128-CBC function. PayBreak can be configured to hook arbitrary functions, including that custom AES function, and record the parameters, such as the key, passed to it. However, a simpler approach in this case was to hook the Windows secure pseudorandom number generator function, CryptGenRandom, which the ransomware (and most others) use to create new session keys per file, and save the output of the function calls.
Recovering files is simply testing each of the recorded session keys with the encrypted files, until a successful decryption. Decrypting my file system of ~1000 files took 94 minutes.
Encrypted: Desert.jpg.WNCRY
Key used by Wannacry: cc24d9c8388fa566456ccec745e009c8
Decrypted: Desert.jpg
We held our annual ACE-CSR event in November 2016. The last talk was my inaugural lecture to full professor. I did not write the summary below myself, hence the use of third person, not because I now consider myself royalty! 🙂
In introducing Jens Groth, professor of cryptology, George Danezis, head of the information security group, commented that Groth’s work provided the only viable solutions to many of the hard privacy problems he himself was tackling. To most qualified engineers, he said, the concept of zero-knowledge proofs seems impossible: the idea is to show the properties of a secret without revealing them. A zero-knowledge proof could, for example, verify the result of a computation on some data without revealing the data itself. Most engineers believe that you must choose between integrity and confidentiality; Groth has proved this is not true. In addition, Danezis praised Groth’s work as highly creative, characterised by great mathematical depth and subtlety, and admired Groth’ willingness to speak his mind fearlessly even to government funders. Angela Sasse, head of the department, called Groth’s work “security tools we’re going to need for future generations”, and noted that simultaneously with these other accomplishments Groth helped put in place the foundation for the group as it is today.
Groth, jokingly opted to structure his talk around papers he’s had rejected to illustrate how hard it can be to publish innovative research. The concept of zero-knowledge proofs originated with a 1985 paper by Shafi Goldwasser, Silvio Micali, and Charles Rackoff. Zero-knowledge proofs have three characteristics: completeness (the prover can convince the verifier that the statement is true); soundness (the claiming prover cannot convince the verifier when the statement is false); and secrecy (no information other than the truth of the statement is leaked, even when the prover is interacting with a verifier who cheats). Groth illustrated the latter idea with a simple card trick: he asked an audience member to choose a card and then say whether the card was a heart or not. If the respondent shows all the cards that are not hearts, counting these proves that the selected card must be a heart without revealing what it is.
Zero-knowledge proofs can be extended to think about more complicated statements. Groth listed some examples:
Assert that a logical formula has an assignment to the variables that makes it true
Verify that a graph is Hamiltonian – that is, there is a path that touches each vertex exactly once
That a set of inputs into a Boolean circuit will produce an output of 1
Any statement of the general form U belongs to some NP-language L
Groth could see many possible applications for these proofs: signatures, encryption, electronic cash, electronic auctions, internet voting, multiparty computation, and verifiable cloud computing. His overall career has focused on building versatile and efficient proofs with the goal of moving them from being expensive and slow to being just a fraction of the cost of the task that’s being executed so that people would stop thinking about the cost and just toss them in as a standard part of any transaction.
The introduction of ZCash, and subsequentarticles explaining the technology, brought (slightly more) mainstream attention to a situation that people interested in blockchain technology have been aware of for quite a while: Bitcoin doesn’t provide users with a lot of anonymity.
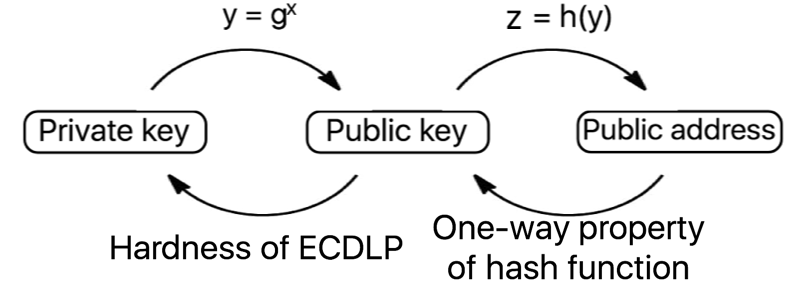
Bitcoin instead provides a property referred to as pseudonymity (derived from pseudonym, meaning ‘false name’). Spending and receiving bitcoin can be done without transacting parties ever learning each other’s off-chain (real world) identities. Users have a private key with which to spend their funds, a public key so that they can receive funds, and an address where the funds are stored, on the blockchain. However, even if addresses are frequently changed, very revealing analysis can be performed on the information stored in the blockchain, as all transactions are stored in the clear.
For example, imagine if you worked at a small company and you were all paid in bitcoin – based on your other purchases, your colleagues could have a very easy time linking your on-chain addresses to you. This is more revealing than using a bank account, and we want cryptocurrencies to offer better properties than bank accounts in every way. Higher speed, lower cost and greater privacy of transfers are all essential.
ZCash is a whole different ball game. Instead of sending transactions in the clear, with the transaction value and sender and recipient address stored on the blockchain for all to see, ZCash transactions instead produce a zero-knowledge proof that the sender owns an amount of ZEC greater than or equal to the amount that they are trying to spend.
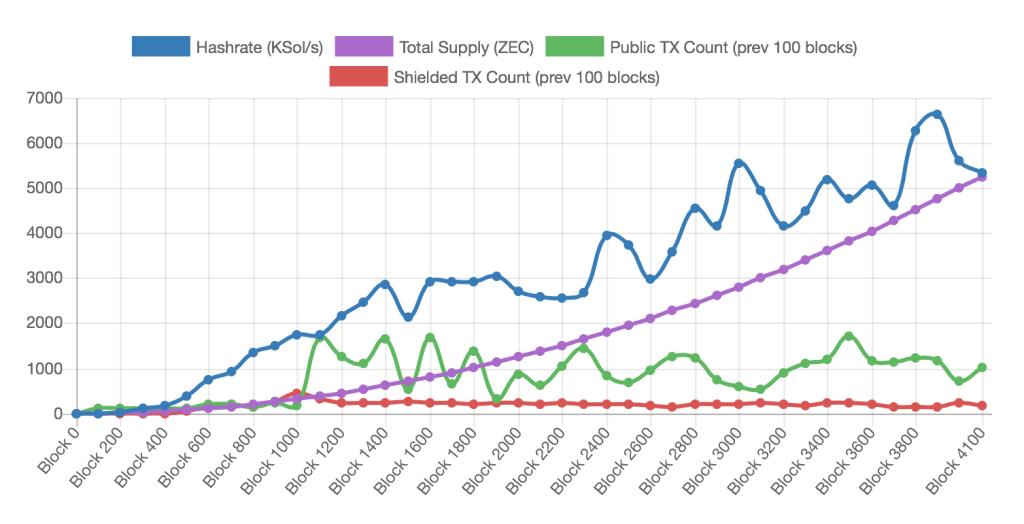
Put more simply, you can submit a proof that you have formed a transaction properly, rather than submitting the actual transaction to be stored forever on the blockchain. These proofs take around 40 seconds to generate, and the current supply of ZCash is a very limited 7977 ZEC. So I’m going to take you through some privacy enhancing methods that work on top of Ethereum, a cryptocurrency with approximately 15 second blocktimes and a current market cap of nearly $1 billion. If we do everything right, our anonymous transactions might even be mined before the ZCash proof has even finished generating.
Currently 229/(7748+229)=2.87% of ZEC is stored in ‘shielded’ accounts, the rest (97.13%) is in a state with Bitcoin-like privacy properties. Stats and graph: Zchain.
Blockchains
If a lot of the words above meant nothing to you, here’s a blockchain/Bitcoin/Ethereum/smart contract primer. If you already have your blockchain basics down, feel free to skip to part 2.
Bitcoin
Satoshi Nakamoto introduced the world to the proof-of-work blockchain, through the release of the bitcoin whitepaper in 2008, allowing users and interested parties to consider for the first time a trustless system, with which it is possible to securely transfer money to untrusted and unknown recipients. Since its launch, the success of bitcoin has motivated the creation of many other cryptocurrencies, both those built upon Bitcoin’s underlying structure, and those built entirely independently.
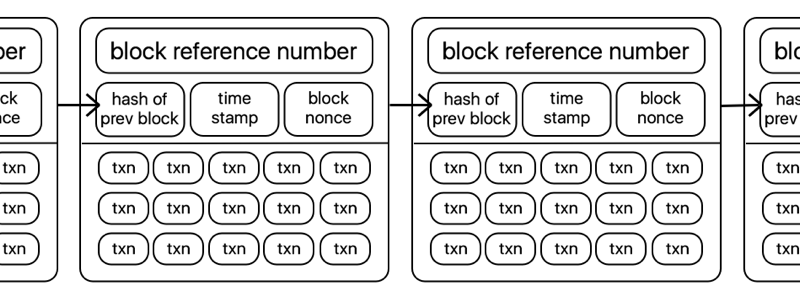
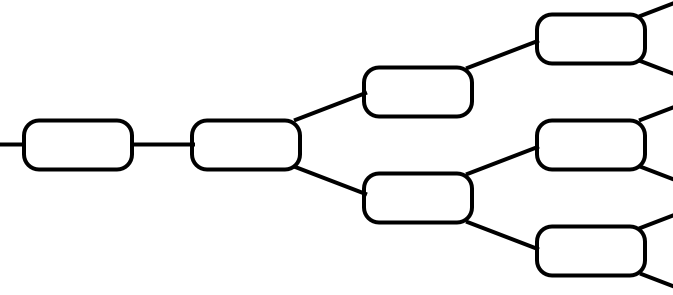
Cryptocurrencies are most simply described as ‘blockchains’ with a corresponding token or coin, with which you can create transactions that are then verified and stored in a block on the underlying blockchain. Put even more simply, they look a little like this:
Transactions in bitcoin are generally simple transfers of tokens from one account to another, and are stored in a block in the clear, with transaction value, sender, and recipient all available for any curious individual to view, analyse, or otherwise trace.
The blockchain has a consensus algorithm. This is essential for construction of one agreed-upon set of transactions, rather than multiple never-converging views of who currently owns which bitcoins.
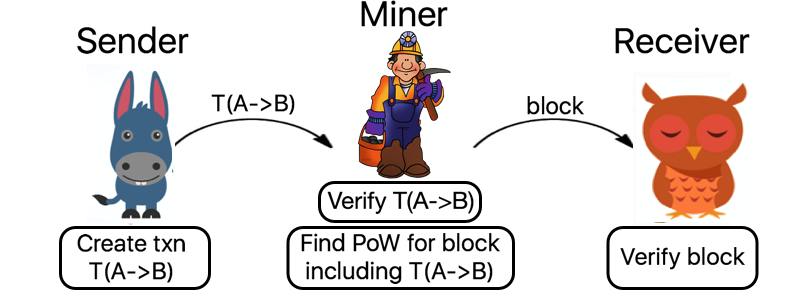
The most common consensus algorithms in play at the moment are ‘proof of work’ algorithms, which require a computationally hard ‘puzzle’ to be solved by miners (a collection of competing participants) in order to make the cost of subverting or reversing transactions prohibitively expensive. Transactions are verified and mined as follows:
To really understand how the privacy enhancing protocol conceived and implemented during my Master’s thesis works, we need to go a little deeper into the inner workings of a blockchain platform called Ethereum.
Ethereum: Programmable Money
In response to the limitations of Bitcoin’s restricted scripting language (you can pretty much only transfer money from A to B with Bitcoin, for security reasons), the Ethereum platform was created, offering an (almost) Turing-complete distributed virtual machine atop the Ethereum blockchain, along with a currency called Ether. The increased scripting ability of the system enables developers to create ‘smart contracts’ on the blockchain, programs with rich functionality and the ability to operate on the blockchain state. The blockchain state records current ownership of money and of the local, persistent storage offered by Ethereum. Smart contracts are limited only by the amount of gas they consume. Gas is a sub-currency of the Ethereum system, existing to impose a limit on the amount of computational time an individual contract can use.
The arrows along the top show how to produce each piece of data from the previous. The labels on the bottom arrows are ‘known hard problems’, which cannot feasibly be solved with today’s computing power.
Ethereum accounts take one of two forms – either they are ‘externally owned’ accounts, controlled with a private key (like all accounts in the bitcoin system), or ‘contracts’, controlled by the code that resides in the specific address in question. Contracts have immutable code stored at the contract address, and additional storage which can be read from and written to by the contract. An Ethereum transaction contains the destination address, optional data, the gas limit, the sequence number and signature authorising the transaction. If the destination address corresponds to a contract, the contract code is then executed, subject to the gas limit as specified in the transaction, which is used to allow a certain number of computational steps before halting.
The ability to form smart contracts suggests some quite specific methods of addressing the lack of privacy and corresponding potential lack of fungibility of coins in the Ethereum system. Although cryptocurrencies provide some privacy with the absence of identity related checks required to buy, mine, or spend coins, the full transaction history is public, enabling any motivated individual to track and link users’ purchases. This concept heavily decreases the fungibility of cryptocurrencies, allowing very revealing taint analysis of coins to be performed, and leading to suggestions of blacklisting coins which were once flagged as stolen.
With smart contracts, we can do magical things, starting in part 2
Why do we need security on wearable devices? The primary reason comes from the fact that, being in direct contact with the user, wearable devices have access to very private and sensitive user’s information more often than traditional technologies. The huge and increasing diversity of wearable technologies makes almost any kind of information at risk, going from medical records to personal habits and lifestyle. For that reason, when considering wearables, it is particularly important to introduce appropriate technologies to protect these data, and it is primary that both the user and the engineer are aware of the exact amount of collected information as well as the potential threats pending on the user’s privacy. Moreover, it has also to be considered that the privacy of the wearable’s user is not the only one at risk. In fact, more and more devices are not limited to record the user’s activity, but can also gather information about people standing around.
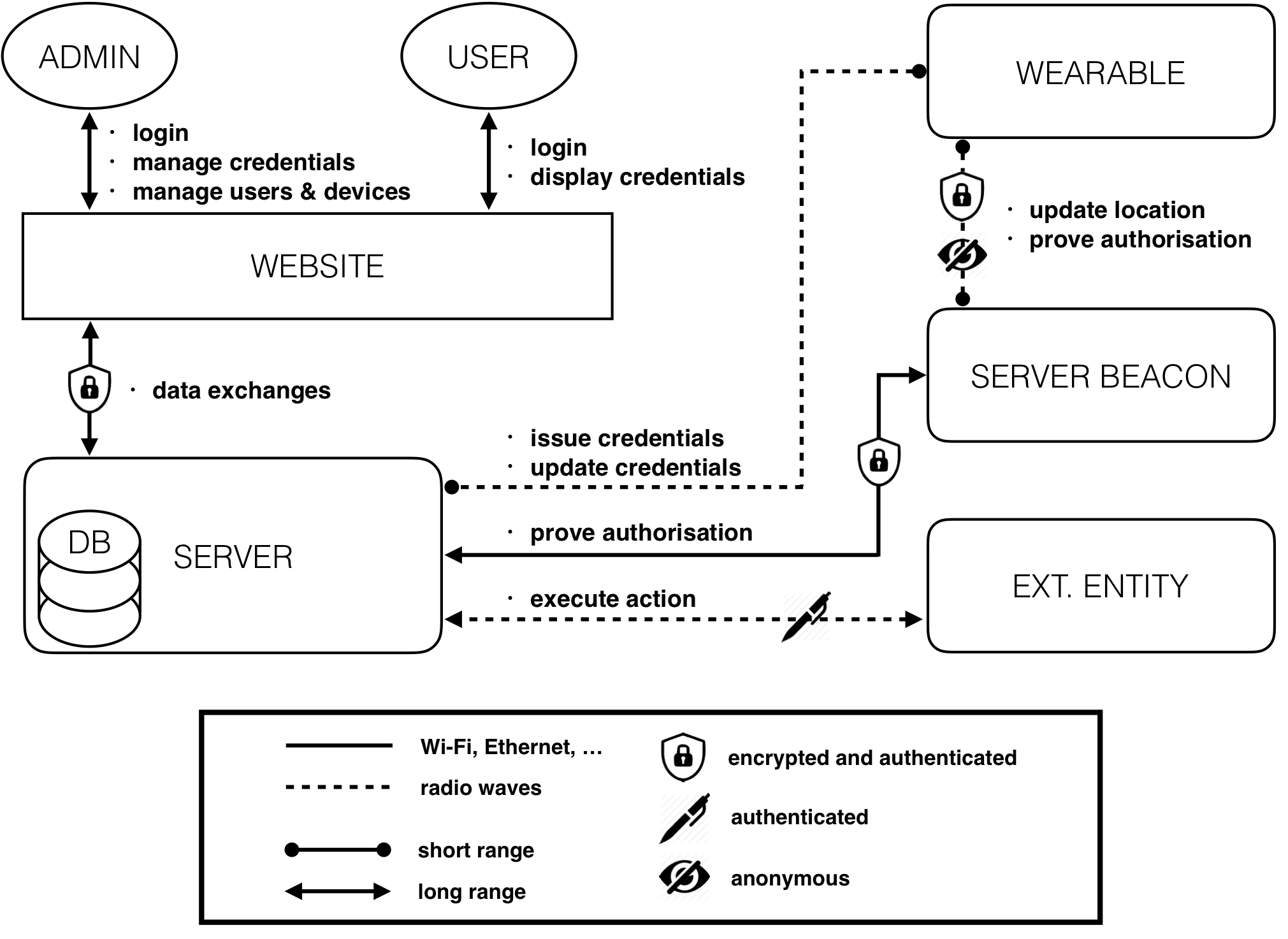
This blog post presents a flexible privacy enhancing system from its architecture to the prototyping level. The system takes advantage from anonymous credentials and is based on the protocols developed by M. Chase, S. Meiklejohn, and G. Zaverucha in Algebraic MACs and Keyed-Verification Anonymous Credentials. Three main entities are involved in this multi-purpose system: a main server, wearable devices and localisation beacons. In this multipurpose architecture, the server firstly issue some anonymous credentials to the wearables. Then, each time a wearable reach a particular physical location (gets close to a localisation beacon) where it desires to perform an action, it starts presenting its credentials in order to ask the server the execution of that a particular action. Both the design of the wearable and the server remain generic and scalable in order to encourage further enhancements and easy integration into real-world applications; i.e., the central server can manage an arbitrary number of devices, each device can posses an arbitrary number of credentials and the coverage area of the localisation system is arbitrarily extendable.
Architecture
The complete system’s architecture can be modelled as depicted in the figure below. Roughly speaking, a web interface is used to manage and display the device’s functions. Each user and admin access the system from that interface.
During the setup phase, the server issues the credentials to a selected device (according to the algorithms presented in Algebraic MACs and Keyed-Verification Anonymous Credentials) granting it a given privilege level. The credentials’ issuance is a short-range process. In fact, the wearable needs to be physically close to the server to allow the admins to physically verify, once and for all, the identity of the wearables’ users. In order to improve security and battery life, the wearable only communicates using extremely low-power and short-range radio waves (dotted line on the figure). The server beacons can be seen as continuities of the main server and have essentially two roles: the first is to operate as an interface between the wearables and the server, and the second is to act as a RF localisation system. Each time the wearable granted with enough privileges reaches some particular physical location (gets close to a localisation beacon), it starts presenting its credentials in order to prove to the server that it possesses credentials over some attributes (without revealing them), and that these credentials have been previously issued by the server itself. Note that the system preserves anonymity only if many users are involved (for each privilege level), but this is a classic requirement of anonymous systems. Finally, once the credentials have been successfully verified by the server, the server issues a signed request to an external entity (which can be, for instance, an automatic door, an alarm system or any compatible IoT entity) to perform the requested action.
We recently had our annual conference for the Academic Centres of Excellence in the UK and I am proud that Jonathan Bootle from UCL won the PhD student elevator pitch competition. I’ll now hand over the rest of the blog post to Jonathan to explain the communication reduction technique for zero-knowledge arguments he presented.
— Jens Groth
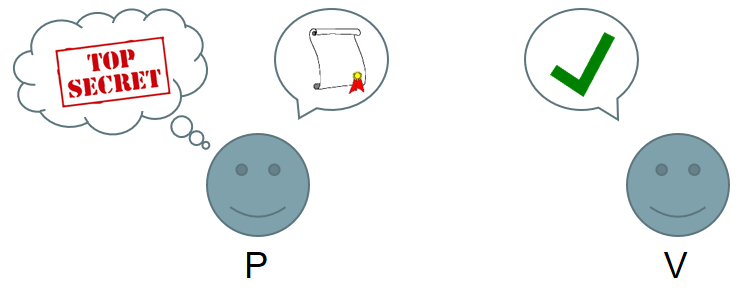
In zero-knowledge arguments, a verifier wants to check that a prover possesses secret knowledge satisfying some stated conditions. The prover wants to convince the verifier without disclosing her secrets. Security is based on cryptographic assumptions, like the discrete logarithm assumption. In 1997, Cramer and Damgård produced a discrete log argument requiring the prover to send N pieces of data to the verifier, for a statement of size N. Groth improved this to √N in 2009 and for five years, this was thought to be the best possible. That is, until cryptographers at UCL, including myself, discovered an incredible trick, which shattered the previous record. So how does it work?
The first step is to compile the statement into the correct format for our protocol. Existing compilers take practical statements, such as verifying the correct execution of a C program, and convert them into a type of circuit. We then convert this circuit into a vector equation for the verifier to check. A circuit of size N produces a vector of size roughly N. So far, so good.
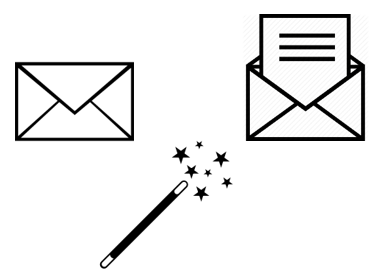
We also need use a commitment scheme, which works like a magician’s envelope. By committing to a hidden value, it can be fixed, and revealed later.
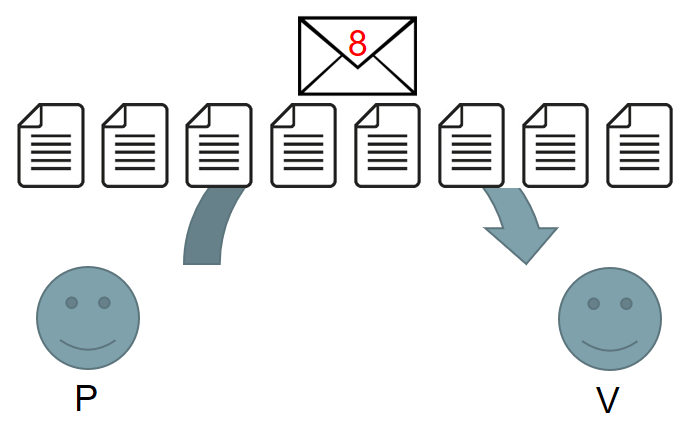
In previous works in the discrete logarithm setting, the prover commits to the vector using a single commitment.
Later the prover reveals the whole vector. This gives high communication costs, and was a major bottleneck.
We discovered a rare and extraordinary property of the commitment scheme which allowed us to cut a vector in half and compress the two halves together. Applying the same trick repeatedly produces a single value which is easy to send, and drastically reduces the communication costs of the protocol.
We begin with a vector of roughly N elements. If we repeatedly cut the vector in half, it takes log(N) cuts to produce a vector containing only a single element. Each time that the prover cuts a vector in half, they must make new commitments to enable the verifier to check the shorter vectors produced. Overall, roughly log(N) new commitments are produced, so the prover must send about log(N) values to the verifier. This is a dramatic improvement from √N. To put this in perspective, doubling the size of the statement only adds a constant amount of data for the prover to send.
Of course, it is possible to base security on other cryptographic assumptions, but other efficient protocols often use very strong and untested assumptions which have yet to receive a high level of scrutiny. By contrast, the discrete logarithm assumption has been used and studied for over three decades.
Is this just a theoretical advance? Far from it. Our protocol has a working Python implementation, which has been extensively benchmarked. By combining our code with the compilers that I mentioned earlier, we verified the correct execution of C programs. By sending under 7kB of data each time, we can verify matrix multiplications, simulations of the motion of gas molecules, and SHA-1 hashes. It’s nice to see theory that compiles and works.
The full paper is by Jonathan Bootle, Andrea Cerulli, Pyrros Chaidos, Jens Groth and Christophe Petit and was published at EUROCRYPT 2016.
Internet voting is a hard problem: there are many ways to fail, and the cost of failing is high. Furthermore, the security requirements appear to be self-contradicting at times. Verifiability requires that a voter, let’s say Alice, must have sufficient knowledge about her ballot to detect if it was tampered with, while Privacy requires that Alice’s vote remains secret, even if Alice herself is bribed or forced into revealing everything she knows.
Can we build a system that allows Alice to verify that her ballot remains unchanged, but also allows her to “forget” who she voted for?
In joint work with Véronique Cortier, Georg Fuchsbauer and David Galindo we present a solution to this problem, in the form of BeleniosRF. We use rerandomizable encryption to change how ballots are encrypted without changing their contents. Digital signatures and zero knowledge techniques ensure ballot integrity, and prevent any tampering during the rerandomization.
Verifiability and privacy
Verifiability means that there must be some way for voters to monitor the election such that they can detect foul play from other voters, or even officials. This is often split into two notions: individual verifiability, dealing with a voter monitoring the way her vote was processed (i.e. that it was not changed or simply thrown away), and universal verifiability, covering requirements for the entirety of the election (e.g. “every ballot must be valid”).
Privacy, in its simplest form, keeps the contents of a vote secret from malicious observers, or even authorities and other compromised voters. In plain terms, we don’t want hackers to decrypt votes, and we don’t allow authorities to decrypt votes when they’re not supposed to; current systems anonymize votes by shuffling or summing them before they are decrypted.
Unfortunately, the above discussion fails to cover one potential adversary: the voter herself. An adversarial voter might be fully corrupt, as in the case of a vote seller who does not value her vote apart from any potential financial gain, or simply be placed in a coercive environment where she is “encouraged” to vote the “right” way. A good voting system should aim to hinder vote sellers and protect coerced users. This might not be possible in all cases: if a voter is monitored 24/7 or simply prevented from voting, the problem may well be unsolvable.
Contactless card payments are fast and convenient, but convenience comes at a price: they are vulnerable to fraud. Some of these vulnerabilities are unique to contactless payment cards, and others are shared with the Chip and PIN cards – those that must be plugged into a card reader – upon which they’re based. Both are vulnerable to what’s called a relay attack. The risk for contactless cards, however, is far higher because no PIN number is required to complete the transaction. Consequently, the card payments industry has been working on ways to solve this problem.
The relay attack is also known as the “chess grandmaster attack”, by analogy to the ruse in which someone who doesn’t know how to play chess can beat an expert: the player simultaneously challenges two grandmasters to an online game of chess, and uses the moves chosen by the first grandmaster in the game against the second grandmaster, and vice versa. By relaying the opponents’ moves between the games, the player appears to be a formidable opponent to both grandmasters, and will win (or at least force a draw) in one match.
Similarly, in a relay attack the fraudster’s fake card doesn’t know how to respond properly to the payment terminal because, unlike a genuine card, it doesn’t contain the cryptographic key known only to the card and the bank that verifies the card is genuine. But like the fake chess grandmaster, the fraudster can relay the communication of the genuine card in place of the fake card.
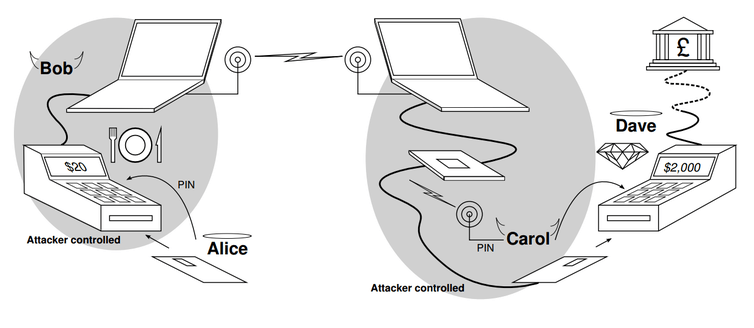
For example, the victim’s card (Alice, in the diagram below) would be in a fake or hacked card payment terminal (Bob) and the criminal would use the fake card (Carol) to attempt a purchase in a genuine terminal (Dave). The bank would challenge the fake card to prove its identity, this challenge is then relayed to the genuine card in the hacked terminal, and the genuine card’s response is relayed back on behalf of the fake card to the bank for verification. The end result is that the terminal used for the real purchase sees the fake card as genuine, and the victim later finds an unexpected and expensive purchase on their statement.
The relay attack, where the cards and terminals can be at any distance from each other
In our scenario, the victim put their card in a fake terminal thinking they were buying a coffee when in fact their card details were relayed by a radio link to another shop, where the criminal used a fake card to buy something far more expensive. The fake terminal showed the victim only the price of a cup of coffee, but when the bank statement arrives later the victim has an unpleasant surprise.
At the time, the banking industry agreed that the vulnerability was real, but argued that as it was difficult to carry out in practice it was not a serious risk. It’s true that, to avoid suspicion, the fraudulent purchase must take place within a few tens of seconds of the victim putting their card into the fake terminal. But this restriction only applies to the Chip and PIN contact cards available at the time. The same vulnerability applies to today’s contactless cards, only now the fraudster need only be physically near the victim at the time – contactless cards can communicate at a distance, even while the card is in the victim’s pocket or bag.
On Thursday, Microsoft won an important federal appeals court case against the US government. The case centres on a warrant issued in December 2013, requiring Microsoft to disclose emails and other records for a particular msn.com email address which was related to a narcotics investigation. It transpired that these emails were stored in a Microsoft datacenter in Ireland, but the US government argued that, since Microsoft is a US company and can easily copy the data into the US, a US warrant would suffice. Microsoft argued that the proper way for the US government to obtain the data is through the Mutual Legal Assistance Treaty (MLAT) between the US and Ireland, where an Irish court would decide, according to Irish law, whether the data should be handed over to US authorities. Part of the US government’s objection to this approach was that the MLAT process is sometimes very slow, although though the Irish government has committed to consider any such request “expeditiously”.
The appeal court decision is an important victory for Microsoft (following two lower courts ruling against them) because they sell their european datacenters as giving their european customers confidence that their data will be subject to the more stringent european privacy laws. Microsoft’s case was understandably supported by other technology companies in the same position, as well as civil liberties organisations such as the Electronic Frontier Foundation in the US and the Open Rights Group in the UK. However, I have mixed opinions about the outcome: while probably the right decision in this case, the wider consequences could be detrimental to privacy.
Both sides of the case wanted to set a precedent (if not legally, at least in practice). The US government wanted US law to apply to data held by US companies, wherever in the world the data resides. Microsoft wanted the location of the data to imply which legal regime applied, and so their customers could be confident that their own country’s laws will be respected, provided Microsoft have a datacenter in their own country (or at least one with compatible laws). My concern is that this ruling will give false assurance to customers of US companies, because in other circumstances a different decision could quite easily be taken.
We know about this case because Microsoft chose to challenge it in court, and were able to do so. This is the first time Microsoft has challenged a US warrant for data stored in their Irish datacenter despite it being in operation for three years prior to the case. Had the email address been associated with a more serious crime, or the demand for emails accompanied by a gagging order, it may not have been challenged. Microsoft and other technology companies may still choose to accept, or may even be forced to accept, the applicability of future US warrants to data they control, regardless of the court decision last week. One extreme approach to compel this approach would be for the US to jail employees until their demands are complied with.
For this reason, I have argued that control over data is more important than where data resides. If a company does not have the technical capability to comply with an order, it is easier for them to defend their case, and so protects both the company’s customers and staff. Microsoft have taken precisely this approach for their new German datacenters, which will be operated by staff in Germany working for a German “data trustee” (Deutsche Telekom). In contrast to their Irish datacenter, Microsoft staff will be unable to access customer data, except with the permission of and oversight from the data trustee.
While the data trustee model resists information being obtained through improper legal means, a malicious employee could still break rules for personal gain, or the systems designed to process legal requests could be hacked into. With modern security techniques it is possible to do better. End-to-end encryption for instant messaging is one such example, because (if designed properly) the communications provider does not have access to messages they carry. A more sophisticated approach is “distributed consensus”, where a decision is only taken if a majority of participants agree. The consensus process is automated and enforced through cryptography, ensuring that rules are respected even if some participants are malicious. Critical decisions in the Tor network and in Bitcoin are taken this way. More generally, there is a growing recognition that purely legal or procedural mechanisms are insufficient to protect privacy. This is one of the common threads present in much of the research presented at the Privacy Enhancing Technologies Symposium, being held this week in Darmstadt: recognising that there will always be imperfections in software, people and procedures and showing that nevertheless individual’s privacy can still be protected.
Members of the UCL information security group visiting the Aarhus rainbow panorama
The workshop was organized by CFEM and CTIC, and took place in Aarhus from May 30 until June 3, 2016. The speakers presented both theoretical advancements and practical implementations (e.g., voting, auction systems) of MPC, as well as open problems and future directions.
The first session of the second day included two presentations on theoretical results which introduced a series of three-round secure two-party protocols and their security guarantees, and fast circuit garbling under weak assumptions. On the practical side, Rafael Pass presented formal analysis of the block-chain, and abhi shelat outlined how MPC can enable secure matchings. After the lunch break, probabilistic termination of MPC protocols and low-effort VSS protocols were discussed.
Yuval Ishai and Elette Boyle kicked off the third day by presenting constructions of function secret sharing schemes, and recent developments in the area. After the lunch break, a new hardware design enabling Verifiable ASICs was introduced and the latest progress on “oblivious memories” were discussed.
The fourth day featured presentations on RAMs, Garbled Circuits and a discussion on the computational overhead of MPC under specific adversarial models. Additionally, there was a number of presentations on practical problems, potential solutions and deployed systems. For instance, Aaron Johnson presented a system for private measurements on Tor, and Cybernetica representatives demonstrated Sharemind and their APIs. The rump session of the workshop took place in the evening, where various speakers were given at most 7 minutes to present new problems or their latest research discoveries.
On the final day, Christina Brzuska outlined the connections between different types of obfuscation and one-way functions, and explained why some obfuscators were impossible to construct. Michael Zohner spoke about OT extensions, and how they could be used to improve 2-party computation in conjunction with look-up tables. Claudio Orlandi closed the workshop with his talk on Amortised Garbled Circuits, which explained garbling tricks all the way from Yao’s original work up to the state of the art, and provided a fascinating end to the week.
The Investigatory Powers Bill, being debated in Parliament this week, proposes the first wide-scale update in 15 years to the surveillance powers of the UK law-enforcement and intelligence agencies.
The Bill has several goals: to consolidate some existing surveillance powers currently either scattered throughout other legislation or not even publicly disclosed, to create a wide range of new surveillance powers, and to change the process of authorisation and oversight surrounding the use of surveillance powers. The Bill is complex and, at 245 pages long, makes scrutiny challenging.
The Bill has had its first and second readings in the House of Commons, and has been examined by relevant committees in the Commons. The Bill will now be debated in the ‘report stage’, where MPs will have the chance to propose amendments following committee scrutiny. After this it will progress to a third reading, and then to the House of Lords for further debate, followed by final agreement by both Houses.
These committees were faced with a difficult task of meeting an accelerated timetable for the Bill, with the government aiming to have it become law by the end of 2016. The reason for the haste is that the Bill would re-instate and extend the ability of the government to compel companies to collect data about their users, even without there being any suspicion of wrongdoing, known as “data retention”. This power was previously set out in the EU Data Retention Directive, but in 2014 the European Court of Justice found it be unlawful.
Many questions remain about whether the powers granted by the Bill are justifiable and subject to adequate oversight, but where insights from computer security research are particularly relevant is on the powers to grant law enforcement the ability to bypass normal security mechanisms, sometimes termed “exceptional access”.



{kind=link}
{kind=link}