The Bitcoin whitepaper specifies the risks of revealing owners of addresses. It states that “if the owner of a key is revealed, linking could reveal other transactions that belonged to the same owner.” Five years later, we have seen many projects which look at de-anonymising entities in Bitcoin. Such projects use techniques such as address tagging and clustering to tie many addresses to one entity, making it easier to analyse the movement of funds. However, this is not only limited to Bitcoin but also occurs on alternative cryptocurrencies such as Zcash and Monero. Thus tracing transactions on-chain is a known and studied problem.
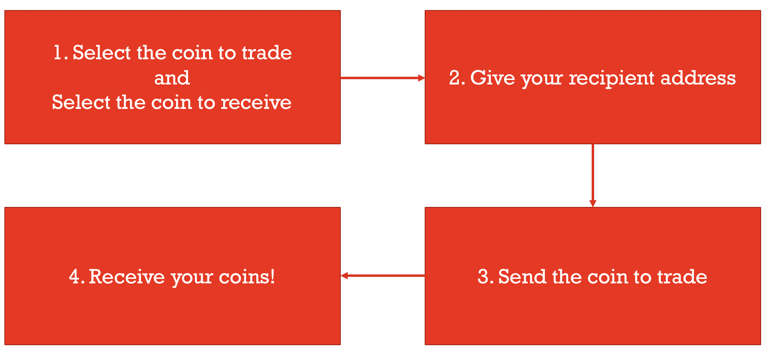
But we have recently seen a shift into entities performing cross-currency trades. For example, the WannaCry hackers laundered over $142,000 Bitcoin from ransoms across cryptocurrencies. The issue here is that cross-chain transactions appear to be indistinguishable from native transactions on-chain. For example, to trade Bitcoin for Monero, one would have to send the exchange bitcoin, and in return, the exchange sends the user some coins in Monero. Both these transactions occur on separate chains and do not appear to be connected, so the actual swap can appear to be obscured. This level of obscurity can be used to hide the original flow of coins, giving users an additional form of anonymity.
Thus it is important to ask whether or not we can analyse such transactions and the extent of the analysis possible, and if so, how? In our paper being presented today at the USENIX Security Symposium, we (Haaroon Yousaf, George Kappos and Sarah Meiklejohn) answer these questions.
Our Research
In summary, we scraped and linked over 1.3 million transactions across different blockchains from the service ShapeShift. In doing so, we found over 100,000 cases where users would convert coins to another currency then move right back to the original one, identified that a Bitcoin address associated with CoinPayments.net address is a very popular service for users to shift to, and saw that scammers preferred shifting their Ethereum to Bitcoin and Monero.
We collected and analysed 13 months of transaction data across eight different blockchains to identify how users interacted with this service. In doing so, we developed new heuristics and identified various patterns of cross-currency trades.
What is ShapeShift?
ShapeShift is a lightweight cross-currency non-custodial service that facilitates trades which allows users to directly trade coins from one currency to another (a cross-currency shift). This service acts as the entity which facilitates the entire trade, allowing users to essentially swap their coins with its own supply. ShapeShift and Changelly are examples of such services.
Continue reading Tracing transactions across cryptocurrency ledgers