In this blog post, we will describe and comment on TESSERACT, a system introduced in a paper to appear at USENIX Security 2019, and previously published as a pre-print. TESSERACT is a publicly available framework for the evaluation and comparison of systems based on statistical classifiers, with a particular focus on Android malware classification. The authors used DREBIN and our MaMaDroid paper as examples of this evaluation. Their choice is because these are two of the most important state-of-the-art papers, tackling the challenge from different angles, using different models, and different machine learning algorithms. Moreover, DREBIN has already been reproduced by researchers even though the code is not available anymore; MaMaDroid’s code is publicly available (the parsed data and the list of samples are available under request). I am one of MaMaDroid’s authors, and I am particularly interested in projects like TESSERACT. Therefore, I will go through this interesting framework and attempt to clarify a few misinterpretations made by the authors about MaMaDroid.
The need for evaluation frameworks
The information security community and, in particular, the systems part of it, feels that papers are often rejected based on questionable decisions or, on the other hand, that papers should be more rigorous, trying to respect certain important characteristics. Researchers from Dutch universities published a survey of papers published to top venues in 2010 and 2015 where they evaluated if these works were presenting “crimes” affecting completeness, relevancy, soundness, and reproducibility of the work. They have shown how the newest publications present more flaws. Even though the authors included their works in the analyzed ones and did not word the paper as a wall of shame by pointing the finger against specific articles, the paper has been seen as an attack to the community rather than an incitement to produce more complete papers. To the best of my knowledge, unfortunately, the paper has not yet been accepted for publication. TESSERACT is another example of researchers’ effort in trying to make the community work more rigorous: most system papers present accuracies that are close to 100% in all the tests done; however, when some of them have been tested on different datasets, their accuracy was worse than a coin toss.
These two works are part of a trend that I personally find important for our community, to allow works that are following other ones on the chronological aspects to be evaluated in a more fair way. I explain with a personal example: I recall when my supervisor told me that at the beginning he was not optimistic about MaMaDroid being accepted at the first attempt (NDSS 2017) because most of the previous literature shows results always over 98% accuracy and that gap of a few percentage points can be enough for some reviewers to reject. When we asked an opinion of a colleague about the paper, before we submitted it for peer-review, this was his comment on the ML part: “I actually think the ML part is super solid, and I’ve never seen a paper with so many experiments on this topic.” We can see completely different reactions over the same specific part of the work.
TESSERACT
The goal of this post is to show TESSERACT’s potential while pointing out the small misinterpretations of MaMaDroid present in the current version of the paper. The authors contacted us to let us read the paper and see whether there has been any misinterpretation. I had a constructive meeting with the authors where we also had the opportunity to exchange opinions on the work. Following the TESSERACT description, there will be a section related to MaMaDroid’s misinterpretations in the paper. The authors told me that the newest versions would be updated according to what we discussed.
TESSERACT is a framework for the evaluation of different systems over the same kind of tests. It is explained through the evaluation of Android malware classification systems. Section 2 is, in fact, an explanation of the rationale behind this work: by using different datasets and different ratios of malware and goodware, the performance of these systems changes dramatically. In the paper, the authors define space and time experimental biases and how these can positively affect the system evaluation. Given these definitions, Section 4 introduces the main contributions of the paper: it first explains space and time constraints that should be taken into consideration according to the author’s judgement, later, the institution of time-aware performance metrics introduces to the algorithm for automatically tuning the system to the highest performance. Section 5 describes possible options for active learning and retraining methods to be applied as part of TESSERACT.
The attempt of the TESSERACT authors is valuable: do we have a way to evaluate papers objectively? In the malware detection field, we currently don’t. We try to evaluate a paper based on how large and up-to-date the sample dataset is, if the methodology has flaws, or if the evaluation is not done properly, but the community doesn’t have any proper framework for this, yet. TESSERACT may have to be refined but is definitely a very interesting attempt. Moreover, TESSERACT can be used with different datasets or in completely different fields.
MaMaDroid misrepresentations in TESSERACT
TESSERACT authors acknowledge at the end of Section 2.1 the full reproducibility and reliability of the results presented in DREBIN and MaMaDroid’s papers, recognising the high scientific standard of the papers.
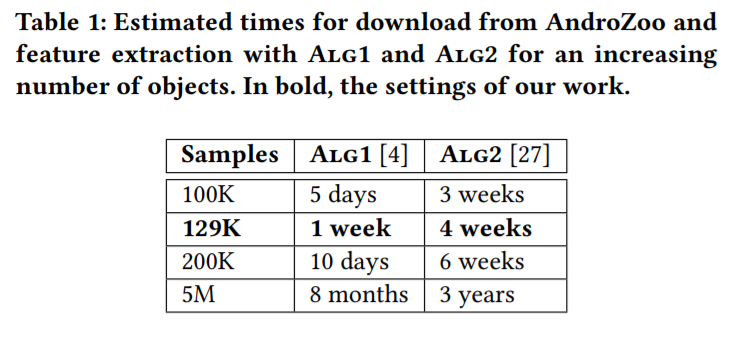
In the first table of the paper, shown below, they present the estimated time for the algorithms’ features extraction. We immediately noticed it was much higher than the one presented in our paper. This estimated time is highly dependent on the set of apps; moreover, there has been a relevant calculation difference: assuming an app market (where a system like MaMaDroid would be implemented) would have much more computational power available than us, I did not take into account the I/O operations each of MaMaDroid scripts had to do. When taken into account, this time is not negligible.
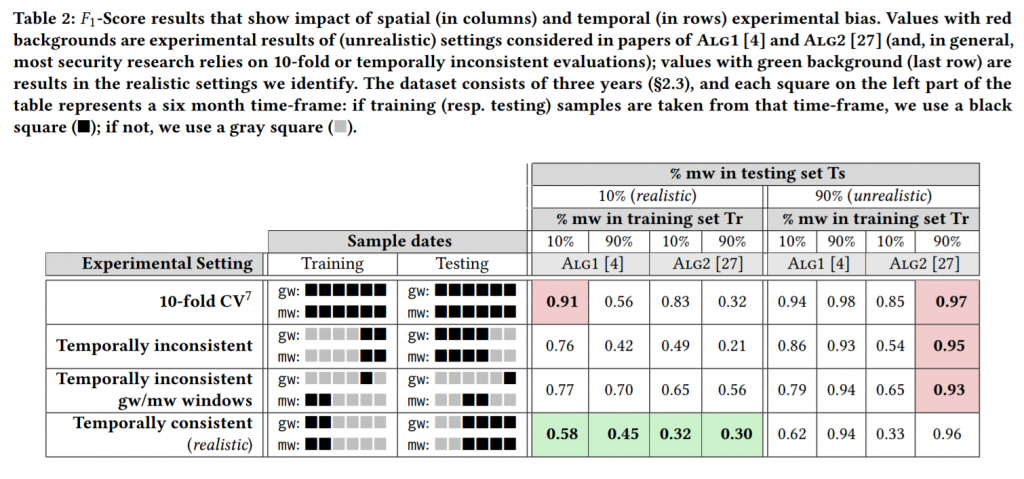
The key point is the second table of the paper, shown below. The authors explain the rationale behind the work: as mentioned earlier when changing datasets and parameters the systems may change their performance dramatically. In the table, the authors colour-coded the different experiments, defining “unrealistic settings considered in papers of…” (Table 2 caption) the red cells and using the green colour for the cells considered realistic settings identified by the TESSERACT authors. MaMaDroid’s red cells are related to experiments using malware samples as 90% of the elements in both training and test set. Only in one specific case, we tested MaMaDroid with a sample ratio close to that one, when the 2014 dataset was used. VirusShare prepared a large 2014 dataset, as the distribution of samples in the dataset may dramatically vary by operating a random subsampling to 40% of the original size (adding biases), we preferred not to subsample.
Another important detail to specify is related to the second constraint in Section 4.1. In the paragraph, the authors introduce the constraint on time consistency between goodware and malware. I completely agree with this constraint, however, it is not the simplest to implement: there may not be the same opportunities for data collection among different research groups. We collected from VirusShare.com over a million malicious samples (the archives do not contain only Android malware) to find the few thousand we used for 2015 and 2016 while the website already selected archives of 2013 and 2014 samples. We have built one of the largest Android malware datasets used in research work, to evaluate our system. Unfortunately, as we did not know about AndroZoo (it has been presented when we were already collecting the samples from other sources), we relied on PlayDrone to collect the old benign samples.
Discussion
As mentioned, I believe this paper has positive relevance to the community. While meeting the authors we had an interesting discussion as I had a different point of view on a temporal constraint they evaluate. The first constraint they take into account in Section 4 is the temporal consistency between training and testing: training samples must be older than testing ones. The point of view of the authors is simple and logical: if the test sample is older, it would be detected by simpler systems such as signature-based systems. I do not agree with this constraint (that has not been taken into account when we evaluated MaMaDroid) for two reasons. Firstly, this kind of test can show whether the system can reliably stand alone and, therefore, more easily cover the fallacies of systems that are used before in the security chain. Secondly, because it is easy to bypass simpler systems (e.g. signature-based ones) by modifying little sample parts that do not influence the behaviour of the malicious code. The last point is considered by the authors as the presence of a completely new sample in the datasets. However, one could counter this point by saying that although the tests violate the first constraint, we can still gain knowledge about what is considered as new samples. Anyway, it has been an amazing discussion point and, if you read until this last section, I would be glad to find your point of view in the comments.
Interesting post. I think you are trying hard to be nice and politically correct, but why don’t you just state what’s clear in the post: that yet another shitty paper misrepresenting what others did in the community made its way to usenix security, perhaps as a result of a shitty review process? I know this maybe not easy to say, but quite clear.
Thanks for your comment (this is politically correct). I always try to be nice and polite but the only politically correct thing written by me is the first sentence of this comment. I spent 2 hours in a meeting with all the authors of the paper to talk about several points of the work that needed clarification. For instance, I disagree with one of their time constraints; I have a different opinion on the definition of new malware samples related to the accuracy of the signature. This does not mean I do not find the paper useful for the community: too many times we have system papers rejected with excuses or, on the other hand, papers that are not using proper datasets or evaluation frameworks. TESSERACT is a little step in making these evaluations more fair and complete. MaMaDroid’s idea of testing with samples categorised by year has been another step as nowadays there are papers applying the same kind of tests.