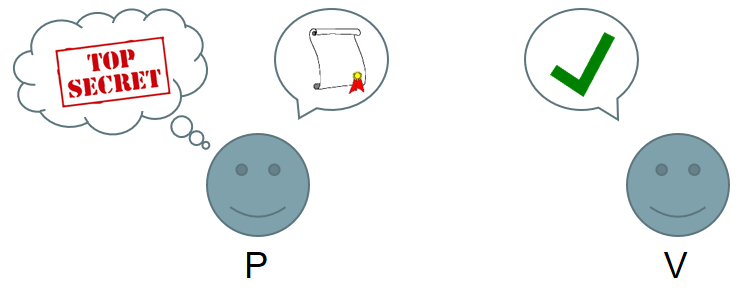
Why do we need security on wearable devices? The primary reason comes from the fact that, being in direct contact with the user, wearable devices have access to very private and sensitive user’s information more often than traditional technologies. The huge and increasing diversity of wearable technologies makes almost any kind of information at risk, going from medical records to personal habits and lifestyle. For that reason, when considering wearables, it is particularly important to introduce appropriate technologies to protect these data, and it is primary that both the user and the engineer are aware of the exact amount of collected information as well as the potential threats pending on the user’s privacy. Moreover, it has also to be considered that the privacy of the wearable’s user is not the only one at risk. In fact, more and more devices are not limited to record the user’s activity, but can also gather information about people standing around.
This blog post presents a flexible privacy enhancing system from its architecture to the prototyping level. The system takes advantage from anonymous credentials and is based on the protocols developed by M. Chase, S. Meiklejohn, and G. Zaverucha in Algebraic MACs and Keyed-Verification Anonymous Credentials. Three main entities are involved in this multi-purpose system: a main server, wearable devices and localisation beacons. In this multipurpose architecture, the server firstly issue some anonymous credentials to the wearables. Then, each time a wearable reach a particular physical location (gets close to a localisation beacon) where it desires to perform an action, it starts presenting its credentials in order to ask the server the execution of that a particular action. Both the design of the wearable and the server remain generic and scalable in order to encourage further enhancements and easy integration into real-world applications; i.e., the central server can manage an arbitrary number of devices, each device can posses an arbitrary number of credentials and the coverage area of the localisation system is arbitrarily extendable.
Architecture
The complete system’s architecture can be modelled as depicted in the figure below. Roughly speaking, a web interface is used to manage and display the device’s functions. Each user and admin access the system from that interface.
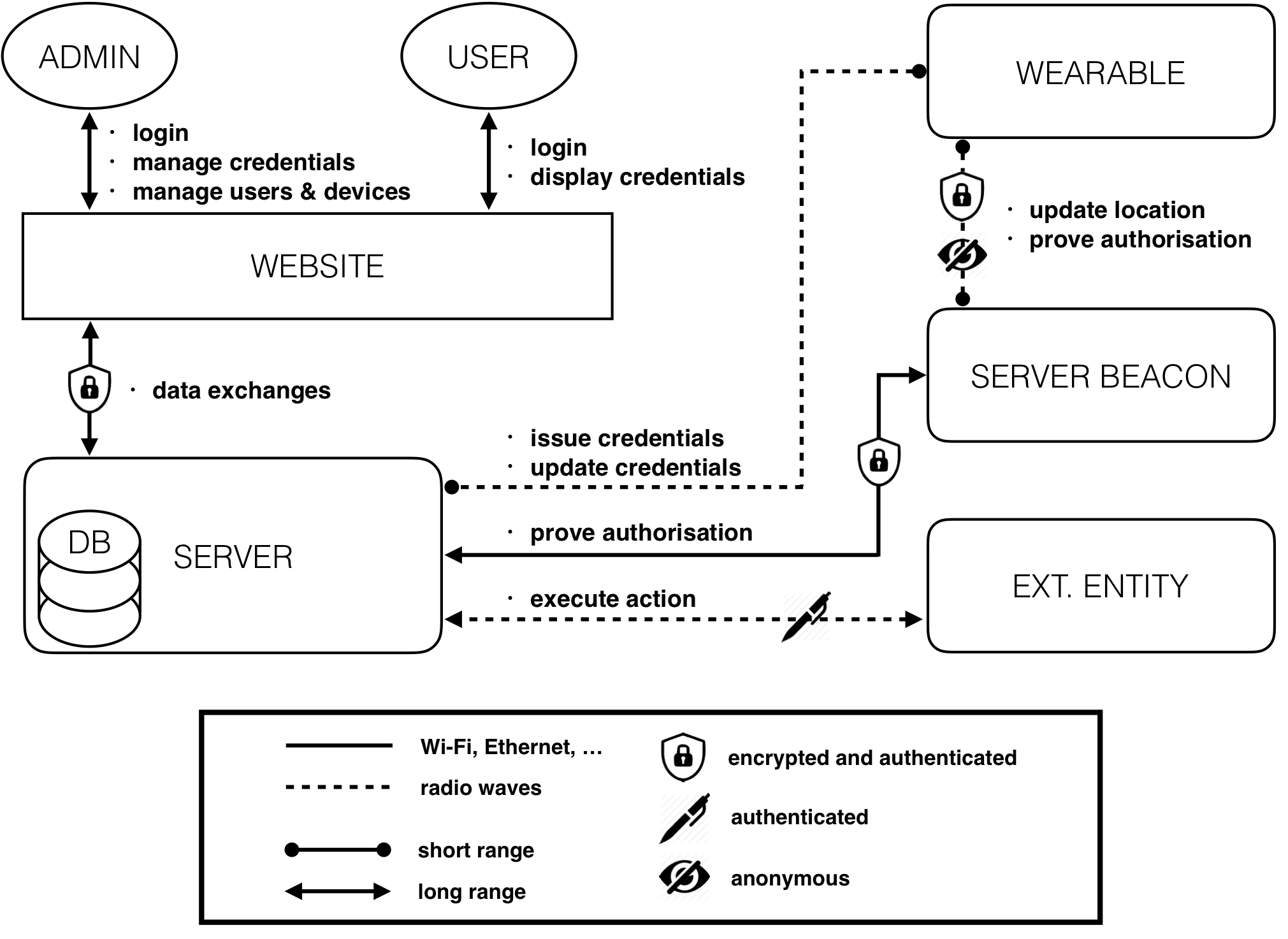
During the setup phase, the server issues the credentials to a selected device (according to the algorithms presented in Algebraic MACs and Keyed-Verification Anonymous Credentials) granting it a given privilege level. The credentials’ issuance is a short-range process. In fact, the wearable needs to be physically close to the server to allow the admins to physically verify, once and for all, the identity of the wearables’ users. In order to improve security and battery life, the wearable only communicates using extremely low-power and short-range radio waves (dotted line on the figure). The server beacons can be seen as continuities of the main server and have essentially two roles: the first is to operate as an interface between the wearables and the server, and the second is to act as a RF localisation system. Each time the wearable granted with enough privileges reaches some particular physical location (gets close to a localisation beacon), it starts presenting its credentials in order to prove to the server that it possesses credentials over some attributes (without revealing them), and that these credentials have been previously issued by the server itself. Note that the system preserves anonymity only if many users are involved (for each privilege level), but this is a classic requirement of anonymous systems. Finally, once the credentials have been successfully verified by the server, the server issues a signed request to an external entity (which can be, for instance, an automatic door, an alarm system or any compatible IoT entity) to perform the requested action.
Continue reading A Privacy Enhancing Architecture for Secure Wearable Devices