Despite the ubiquity of computers in everyday life, resolving a dispute regarding the misuse or malfunction of a system remains hard to do well. A recent example of this is the, now concluded, Post Office trial about the dispute between Post Office Limited and subpostmasters who operate some Post Office branches on their behalf.
Subpostmasters offer more than postal services, namely savings accounts, payment facilities, identity verification, professional accreditation, and lottery services. These services can involve large amounts of money, and subpostmasters were held liable for losses at their branch. The issue is that the accounting is done by the Horizon accounting system, a centralised system operated by Post Office Limited, and subpostmasters claim that their losses are not the result of errors or fraud on their part but rather a malfunction or malicious access to Horizon.
This case is interesting not only because of its scale (a settlement agreement worth close to £58 million was reached) but also because it highlights the difficulty in reasoning about issues related to computer systems in court. The case motivated us to write a short paper presented at the Security Protocols Workshop earlier this year – “Transparency Enhancing Technologies to Make Security Protocols Work for Humans”. This work focused on how the liability of a party could be determined when something goes wrong, i.e., whether a customer is a victim of a flaw in the service provider’s system or whether the customer has tried to defraud the service provider.
Applying Bayesian thinking to dispute resolution
An intuitive way of thinking about this problem is to apply Bayesian reasoning. Jaynes makes a good argument that any logically consistent form of reasoning will lead to taking this approach. Following this approach, we can consider the odd’s form of Bayes’ theorem expressed in the following way.
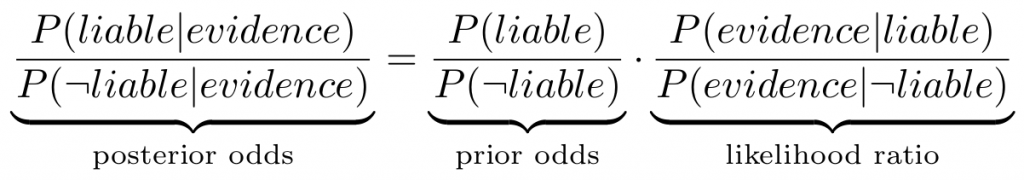
There is a good reason for considering the odd’s form of Bayes’ theorem over its standard form – it doesn’t just tell you if someone is likely to be liable, but whether they are more likely to be liable than not: a key consideration in civil litigation. If a party is liable, the probability that there is evidence is high so what matters is the probability that if the party is not liable there would be the same evidence. Useful evidence is, therefore, evidence that is unlikely to exist for a party that is not liable.
Unfortunately, good evidence is not always a given. Computer systems are full of bugs, so there will be errors whether or not the party administrating the system is liable so the likelihood ratio will tend to one. The prior odds remain, and there bias can creep in. While probabilities can be any value between zero and one, court cases output binary values (liable or not liable). Even if a previous dispute was resolved by the narrowest margin, the odds would naturally be amplified when carried over to the next dispute, under the assumption that the court system got it right.
Consequently, treating disputes on a case by case basis might give a different outcome to treating all disputes together, despite the fact that it should not matter on paper as Bayes’ theorem can be sequentially applied. This result is exemplified by the multitude of individual cases that found subpostmasters liable in contrast to the group litigation that they have won.
Another issue is that all the errors in a computer system are not known, but unknown errors are often left out of any reasoning. In the case of the Post Office trial, an expert witness produced a report that (amongst other things) found that the maximum financial impact of known bugs in Horizon, across all Post Office branches, was £4 million. The report then proposed that the impact on the claimant branches could be obtained by dividing £4 million by 160, due to the claimant branches making up about 1/160th of the transactions of the full branch network. As a result, the total losses by the claimants should be about £25,000, not the £18.7 million they claimed.
This reasoning is flawed because the claimants are not necessarily uniformly sampled from all subpostmasters. They could instead be sampled from subpostmasters that are more likely to have been affected by errors. Once again, we can go back to trying to determine the plausibility of the evidence given the liability (or not) of the parties involved.
Let us assume that subpostmasters are mistaken and that their shortfalls are not related to errors, and that the errors are uniformly distributed. Branches will not be affected equally by errors, but shortfalls are largely the result of something other than errors, so we assume that the occurrence of a bug has a negligible effect on whether a subpostmaster will join the group litigation. Then, we infer that total losses for all the claimant branches, that result from Horizon bugs, will be on average £25,000, being £4 million shared equally over all branches, scaled by their share of transactions.
Because £25,000 is much less than £18.7 million, that indicates that it is very likely much of the claimants’ shortfalls are due to causes other than Horizon bugs. However, this argument tells us nothing we didn’t already know because we already assumed that the shortfall is not related to Horizon bugs. Had we not made this assumption, it would not be valid to share losses equally over all transactions.
Let us now consider the alternative scenario. We assume that shortfalls are indeed largely due to Horizon bugs having exhibited themselves. Again, bugs will not affect all branches equally, but only a subpostmaster with branches facing substantial shortfalls will join the group litigation. It may just have been bad luck that a particular bug hit a particular branch, but once it happens, the affected subpostmaster is more likely to join the group litigation. As a result of this selection process, it is much more likely that subpostmasters who joined the group litigation had a shortfall caused by a Horizon bug and hence it is not valid to share the total losses equally over all branches. If the group litigation was well advertised, it’s plausible that almost all of the shortfall resulting from Horizon bugs affects subpostmasters participating in the litigation.
A place for transparency
In the example above, the evidence is consistent with both the subpostmasters being liable and not liable, which is not very helpful for resolving a dispute. From the point of view of system designers, can we provide anything better? Some form of transparency overlay (balanced with privacy requirements) that allows for an overall view of how well the system is functioning (e.g., the error rate) could help.
First, it would allow parties like subpostmasters to be able to judge in the first place whether or not they would like to participate in the system. Second, in case of a dispute, it would be assist external parties judging how reliable the evidence produced by a system is.
One issue with statistical arguments, such as an error rate, is however that they do not explicitly show what has happened in a particular case. If a subpostmaster could point to errors in the system that have affected them specifically, for example by tracking their transactions and identifying errors in the corresponding logs, disputes could be resolved in a much easier way.
Much also depends on the environment, and incentives, in which the system is deployed. As in the case of the Post Office trial, an important issue is the disparity between parties like the Post Office and the subpostmasters. A potential requirement might be that evidence from a system that indicates that someone is liable is only acceptable if the system operator can demonstrate that the system would be able to clear someone innocent.
Closing thoughts
The example discussed here is only one of many examples of a system controlled by one party that can produce negative outcomes for other parties, and where there are important information asymmetries. Payment systems and machine-learning based systems are other common examples. More and more, these systems play a role in legal disputes.
Transparency seems like an intuitive property to focus on in order to address problems of information asymmetry, but there is no established basis to treat transparency like we do other common properties in information security (e.g., confidentiality) that transparency interacts with. This can be problematic, in particular when we discuss transparency for complicated systems (e.g., neural networks) where cause and effect are harder to establish. Maybe what is needed to productively discuss transparency for systems is first develop a set of design principles that cover transparency.