Data is increasingly collected and shared, with potential benefits for both individuals and society as a whole, but people cannot always be confident that their data will be shared and used appropriately. Decisions made with the help of sensitive data can greatly affect lives, so there is a need for ways to hold data processors accountable. This requires not only ways to audit these data processors, but also ways to verify that the reported results of an audit are accurate, while protecting the privacy of individuals whose data is involved.
We (Alexander Hicks, Vasilios Mavroudis, Mustafa Al-Basam, Sarah Meiklejohn and Steven Murdoch) present a system, VAMS, that allows individuals to check accesses to their sensitive personal data, enables auditors to detect violations of policy, and allows publicly verifiable and privacy-preserving statistics to be published. VAMS has been implemented twice, as a permissioned distributed ledger using Hyperledger Fabric and as a verifiable log-backed map using Trillian. The paper and the code are available.
Use cases and setting
Our work is motivated by two scenarios: controlling the access of law-enforcement personnel to communication records and controlling the access of healthcare professionals to medical data.
The UK Home Office states that 95% of serious and organized criminal cases make use of communications data. Annual reports published by the IOCCO (now under the IPCO name) provide some information about the request and use of communications data. There were over 750 000 requests for data in 2016, a portion of which were audited to provide the usage statistics and errors that can be found in the published report.
Not only is it important that requests are auditable, the requested data can also be used as evidence in legal proceedings. In this case, it is necessary to ensure the integrity of the data or to rely on representatives of data providers and expert witnesses, the latter being more expensive and requiring trust in third parties.
In the healthcare case, individuals usually consent for their GP or any medical professional they interact with to have access to relevant medical records, but may have concerns about the way their information is then used or shared. The NHS regularly shares data with researchers or companies like DeepMind, sometimes in ways that may reduce the trust levels of individuals, despite the potential benefits to healthcare.
On the other hand, patients with serious diseases often have trouble getting the treatment they need. Universities conducting academic studies are legally blocked from contacting them, and patients are unaware that such studies are going on. If they do choose to participate in a study, it should be ensured that they can verify their data is accurately represented in the results published.
With this in mind, there is a general setting that can be defined. Our system considers agents (e.g., law enforcement, DeepMind) that request data from data providers (e.g., service providers, NHS) that was collected from individual users. Requests are placed on a log that is accessible to users that check for requests relevant to them and to auditors that perform general audits. Users may also monitor and verify the reports published by auditors. In practice there is also a regulator that is external to our system and defines the policies followed by the above actors in the system.
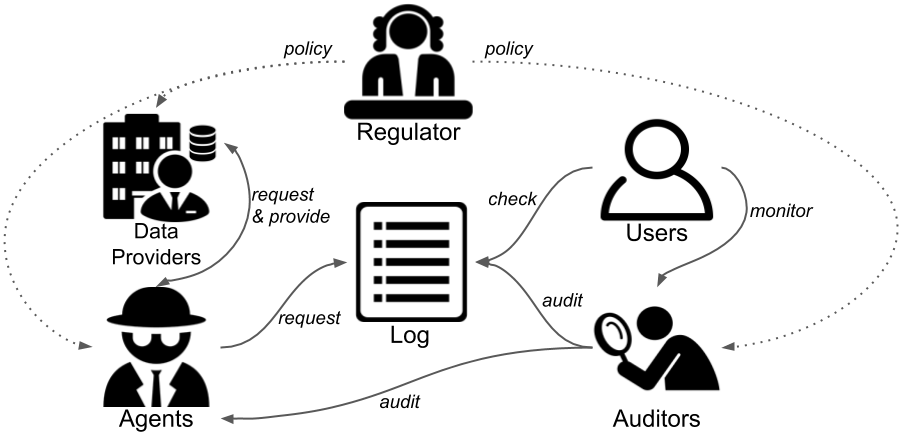
We are concerned with three criteria for this system: auditability, privacy and verifiability. In essence, auditability is about ensuring the integrity of the information on the system, privacy is about ensuring that no information is disclosed that infringes the privacy of participants, and verifiability is about ensuring that information the auditor publishes about hidden data is accurate.
VAMS
In order to build our system, we rely on tamper-resistant ledgers to provide logs (key-value stores) with integrity properties, cryptography for access control to information in the log, and a scheme that allows publicly verifiable and privacy preserving statistics to be published in the log. We use Hyperledger Fabric and Trillian to build the log in two different ways. Both offer similar integrity guarantees through the use of a blockchain or a Merkle Tree, ensuring that users and auditors can detect malicious log servers and any attempt to tamper or delete requests in the log. A ThreeBallot based scheme is used to provide privacy preserving statistics that can be published in the log and verified.
Adding requests to the log is straightforward, but some thought is required to ensure that users will be able to find the requests relevant to them. There is a simple way to do this, although it requires a few assumptions.
In order for users to find requests, they must be able know which key in the log stores a request relevant to them, without communicating with the agent or data provider involved in the request. The information used to determine the key must then be known to all three parties, so we assume the existence of an agent identifier (e.g., passport or national insurance number) and a data provider identifier (e.g., a customer or NHS number). Using one of these as keys and the other (along with an session identifier corresponding to the number of requests done with the same pair of identifiers) as plaintext in a standard encryption scheme like AES, we produce a common identifier that the user can look for in the log. In that way, looking at a request does not reveal the user it is relevant to, and requests cannot be linked together (due to the session identifier) to infer information. To control access to the request information, the request is then encrypted under the public key of the relevant auditors and user.
Checking requests in the log is also straightforward. For a user, they must compute possible common identifiers (accounting for possible values of the session identifier) to find the requests that are relevant to them. Auditors simply retrieve the whole log, or a subset of it, so that they can go through and perform their audit.
Once auditors have accessed the information they need and performed their audits, it remains for them to publish their reports. For their published statistics to be publicly verifiable a dataset must be published that can be used to recompute them. There is then a need to ensure that the dataset cannot be used to infer information other than the statistics themselves. To do this, we use a scheme based on the ThreeBallot voting system. Auditors compute a privacy preserving dataset from the original one and publish it to the log along with statistics. Users can then verify that the data they gave access to was included.
Obtaining the privacy preserving transformed dataset is done by producing shares from the original records (tuples of binary elements). In the simple case where only univariate statistics are needed (e.g., IOCCO reports), it suffices to split a record (tuple) of elements into shares made of one element each. If multivariate statistics are needed, a record is used to produce three shares that are records with some elements taking the false value of the original element.
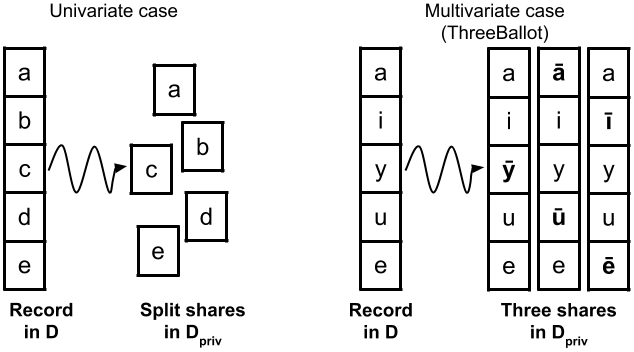
The auditor can tag shares with a share identifier, computed from a share index and the user’s common identifier, to allow users to verify their shares are included in the published dataset of shares when they check the statistics.
Evaluation
We evaluated our implementations based on Hyperledger Fabric and Trillian. In both cases, single log operations (update and retrieval) were in the order of a few milliseconds whilst throughput was 40 and 102 updates/second for Hyperledger Fabric (limited by the client machine) and Trillian (limited by the map server), respectively. In both cases, this is more than enough to handle the 750 000 yearly requests in the law enforcement case, as it averages only 1 request every 9 seconds during work hours. Waiting time for a queued request would only be a few milliseconds.
Both implementations achieved our auditability and privacy goals, with various trade-offs in setup difficulty (in favour of Trillian), audit efficiency (in favour of Trillian), flexibility (in favour of Hyperledger Fabric) and access control (in favour of Hyperledger Fabric). There is also a trade-off in the centralised (Trillian) and decentralised (Hyperledger Fabric) approach, with both perhaps being preferred for different use cases.
For the case of multivariate statistics, the security of the scheme depends on the probability of patterns appearing in the dataset, which translates to bounds on the number of elements in shares and users. Evaluated in the context of association rule learning , it allows high levels of accuracy for 10 000 or more users, a reasonable number in many fields (e.g., studies on genes and protein networks, epidemiology studies).
In summary, VAMS achieves all our auditability, privacy and verifiability goals, based on realistic use cases, illustrating that the current framework for requesting data can be greatly improved to benefit all parties involved. More details can be found in the paper.